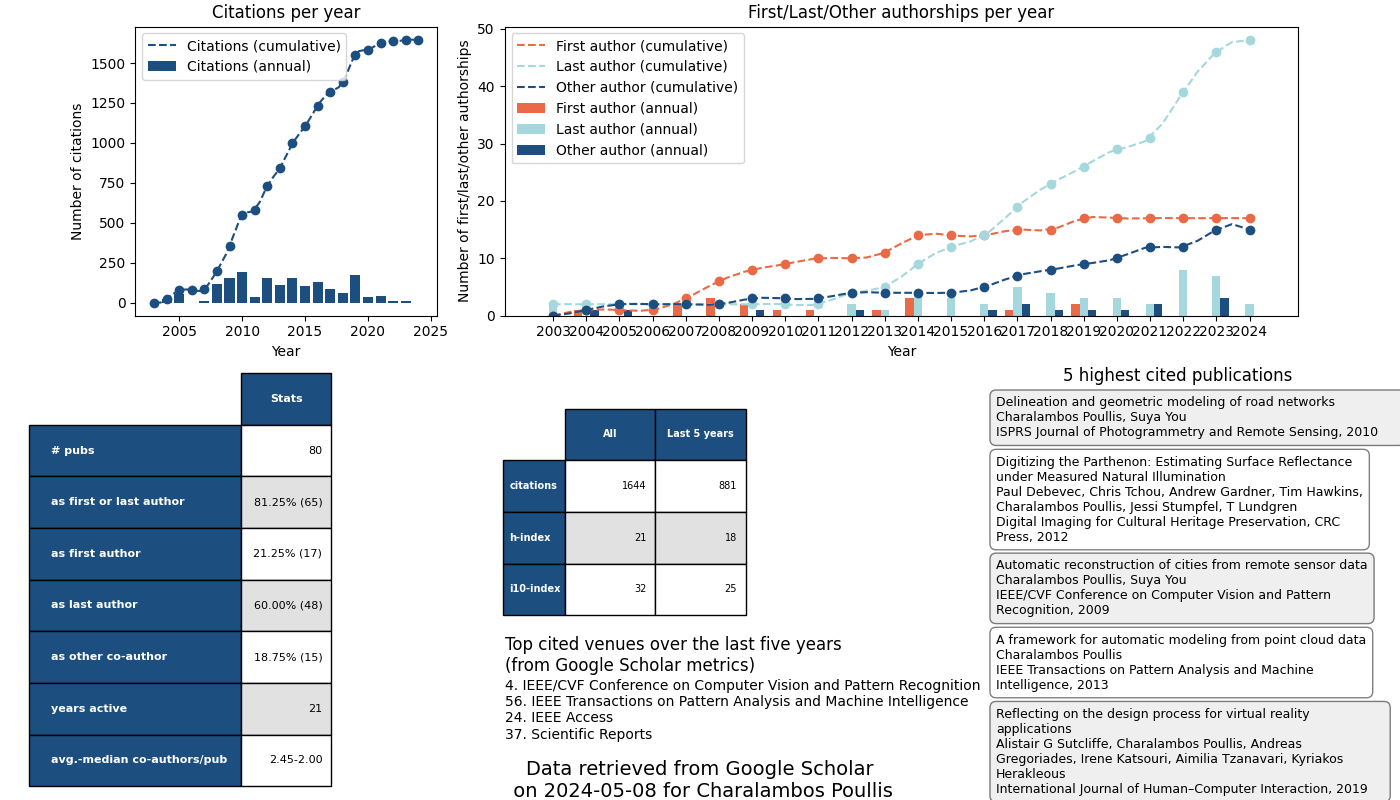
Publications
Data Leakage Detection and De-duplication in Large Scale Geospatial Image Datasets

Abstract
In our study, we conducted a comprehensive analysis of three widely used datasets in the domain of building footprint extraction using deep neural networks: the INRIA Aerial Image Labelling dataset, SpaceNet 2: Building Detection v2, and the AICrowd Mapping Challenge datasets. Our experiments revealed several issues in the AICrowd Mapping Challenge dataset, where nearly 90% (about 250k) of the training split images had identical copies, indicating a high level of duplicate data. Additionally, we found that approximately 56k of the 60k images in the validation split were also present in the training split, amounting to a 93% data leakage. Furthermore, we present a data validation pipeline to address these issues of duplication and data leakage, which hinder the performance of models trained on such datasets. Employing perceptual hashing techniques, this pipeline is designed for efficient de-duplication and leakage identification. It aims to thoroughly evaluate the quality of datasets before their use, thereby ensuring the reliability and robustness of the trained models.
Distill3R: A Pipeline for Democratizing 3D Foundation Models on Commodity Hardware

Abstract
While multi-view 3D reconstruction has shifted toward large-scale foundation models capable of inferring globally consistent geometry, their reliance on massive computational clusters for training has created a significant barrier to entry for most academic laboratories. To bridge this compute divide, we introduce Distill3R, a framework designed to distill the geometric reasoning of 3D foundation models into compact students fully trainable on a single workstation. Our methodology centers on two primary innovations: (1) an offline caching pipeline that decouples heavy teacher inference from the training loop through compressed supervision signals, and (2) a confidence-aware distillation loss that leverages teacher uncertainty to enable training on commodity hardware. We propose a 72M-parameter student model which achieves a 9x reduction in parameters and a 5x inference speedup compared to its 650M-parameter teacher. The student is fully trainable in under 3 days on a single workstation, whereas its teacher requires massive GPU clusters for up to a week. We demonstrate that the student preserves the structural consistency and qualitative geometric understanding required for functional 3D awareness. By providing a reproducible, single-workstation training recipe, Distill3R serves as an exploratory entry point for democratized 3D vision research and efficient edge deployment. This work is not intended to compete with state-of-the-art foundation models, but to provide an accessible research baseline for laboratories without access to large-scale compute to train and specialize models on their own domain-specific data at minimal cost.
Methods and Systems for Real-Time Saccade Prediction
Abstract
The present invention provides a redirected walking system that employs machine learning and artificial intelligence to predict the occurrence of natural saccadic eye movements. By anticipating when users will experience brief periods of reduced visual attention—a phenomenon known as inattentional blindness—the system can apply subtle redirections to the user's virtual trajectory during these windows without conscious detection. This approach eliminates the need for expensive eye-tracking hardware, reduces head-mounted display complexity, and avoids the artificial triggering of major saccades, thereby delivering a more seamless, cost-effective, and user-friendly solution for navigating large-scale virtual environments within limited physical spaces.
Extreme Views: 3DGS Filter for Novel View Synthesis from Out-of-Distribution Camera Poses

Abstract
When viewing a 3D Gaussian Splatting (3DGS) model from camera positions significantly outside the training data distribution, substantial visual noise commonly occurs. These artifacts result from the lack of training data in these extrapolated regions, leading to uncertain density, color, and geometry predictions from the model. To address this issue, we propose a novel real-time render-aware filtering method. Our approach leverages sensitivity scores derived from intermediate gradients, explicitly targeting instabilities caused by anisotropic orientations rather than isotropic variance. This filtering method directly addresses the core issue of generative uncertainty, allowing 3D reconstruction systems to maintain high visual fidelity even when users freely navigate outside the original training viewpoints. Experimental evaluation demonstrates that our method substantially improves visual quality, realism, and consistency compared to existing Neural Radiance Field (NeRF)-based approaches such as BayesRays. Critically, our filter seamlessly integrates into existing 3DGS rendering pipelines in real-time, unlike methods that require extensive post-hoc retraining or fine-tuning. Code and results at this link.
Fast Self-Supervised Depth and Mask Aware Association for Multi-Object Tracking

Abstract
Traditional multi-object tracking (MOT) frameworks often rely on 2D Intersection-over-Union (IoU) for association, which is unreliable under occlusion or when visually similar objects are in close proximity. We propose a novel tracking pipeline that integrates zero-shot monocular depth estimation with promptable visual segmentation to generate fine-grained spatio-structural cues. These fused features are refined through a compact encoder trained with self-supervision, enabling depth-guided association as a standalone similarity cue. To our knowledge, this is the first MOT framework that leverages pixel-level depth-segmentation embeddings as an explicit similarity cue during data association. On challenging MOT benchmarks, our method achieves state-of-the-art identity preservation in cluttered and occluded scenarios.
Depth-Aware Scoring and Hierarchical Alignment for Multiple Object Tracking
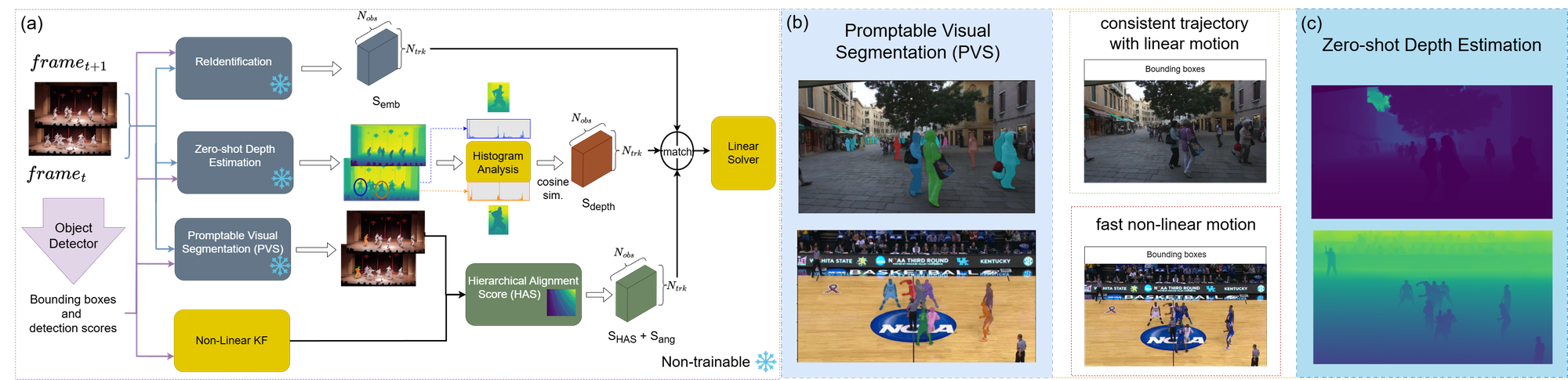
Abstract
Current motion-based multiple object tracking (MOT) approaches rely heavily on Intersection-over-Union (IoU) for object association. Without using 3D features, they are ineffective in scenarios with occlusions or visually similar objects. To address this, our paper presents a novel depth-aware framework for MOT. We estimate depth using a zero-shot approach and incorporate it as an independent feature in the association process. Additionally, we introduce a Hierarchical Alignment Score that refines IoU by integrating both coarse bounding box overlap and fine-grained (pixel-level) alignment to improve association accuracy without requiring additional learnable parameters. To our knowledge, this is the first MOT framework to incorporate 3D features (monocular depth) as an independent decision matrix in the association step. Our framework achieves state-of-the-art results on challenging benchmarks without any training nor fine-tuning. The code is available at https://github.com/Milad-Khanchi/DepthMOT
DSV-LFS: Unifying LLM-Driven Semantic Cues with Visual Features for Robust Few-Shot Segmentation
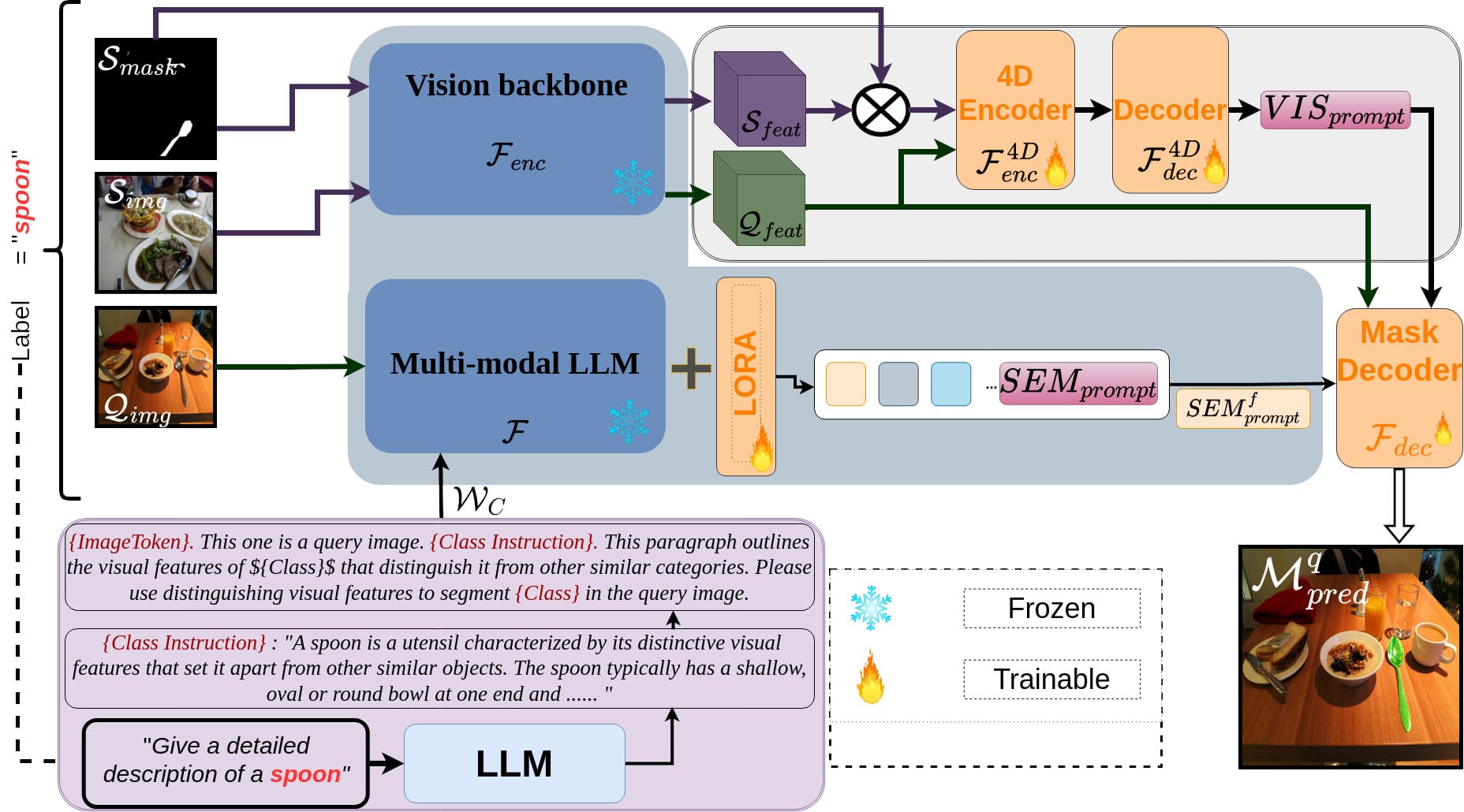
Abstract
Few-shot semantic segmentation (FSS) aims to enable models to segment novel/unseen object classes using only a limited number of labeled examples. However, current FSS methods frequently struggle with generalization due to incomplete and biased feature representations, especially when support images do not capture the full appearance variability of the target class. To improve the FSS pipeline, we propose a novel framework that utilizes large language models (LLMs) to adapt general class semantic information to the query image. Furthermore, the framework employs dense pixel-wise matching to identify similarities between query and support images, resulting in enhanced FSS performance. Inspired by reasoning-based segmentation frameworks, our method, named DSV-LFS, introduces an additional token into the LLM vocabulary, allowing a multimodal LLM to generate a "semantic prompt" from class descriptions. In parallel, a dense matching module identifies visual similarities between the query and support images, generating a "visual prompt". These prompts are then jointly employed to guide the prompt-based decoder for accurate segmentation of the query image. Comprehensive experiments on the benchmark datasets Pascal-5i and COCO-20i demonstrate that our framework achieves state-of-the-art performance-by a significant margin-demonstrating superior generalization to novel classes and robustness across diverse scenarios. The source code is available at https://github.com/aminpdik/DSV-LFS
Pix2Poly: A Sequence Prediction Method for End-to-end Polygonal Building Footprint Extraction from Remote Sensing Imagery

Abstract
Extraction of building footprint polygons from remotely sensed data is essential for several urban understanding tasks such as reconstruction, navigation, and mapping. Despite significant progress in the area, extracting accurate polygonal building footprints remains an open problem. In this paper, we introduce Pix2Poly, an attention-based end-to-end trainable and differentiable deep neural network capable of directly generating explicit high-quality building footprints in a ring graph format. Pix2Poly employs a generative encoder-decoder transformer to produce a sequence of graph vertex tokens whose connectivity information is learned by an optimal matching network. Compared to previous graph learning methods, ours is a truly end-to-end trainable approach that extracts high-quality building footprints and road networks without requiring complicated, computationally intensive raster loss functions and intricate training pipelines. Upon evaluating Pix2Poly on several complex and challenging datasets, we report that Pix2Poly outperforms state-of-the-art methods in several vector shape quality metrics while being an entirely explicit method. Our code is available at https://github.com/yeshwanth95/Pix2Poly
Neural Real-Time Recalibration for Infrared Multi-Camera Systems
Abstract
Currently, there are no learning-free or neural techniques for real-time recalibration of infrared multi-camera systems. In this paper, we address the challenge of real-time, highly-accurate calibration of multi-camera infrared systems, a critical task for time-sensitive applications. Unlike traditional calibration techniques that lack adaptability and struggle with on-the-fly recalibrations, we propose a neural network-based method capable of dynamic real-time calibration. The proposed method integrates a differentiable projection model that directly correlates 3D geometries with their 2D image projections and facilitates the direct optimization of both intrinsic and extrinsic camera parameters. Key to our approach is the dynamic camera pose synthesis with perturbations in camera parameters, emulating realistic operational challenges to enhance model robustness. We introduce two model variants: one designed for multi-camera systems with onboard processing of 2D points, utilizing the direct 2D projections of 3D fiducials, and another for image-based systems, employing color-coded projected points for implicitly establishing correspondence. Through rigorous experimentation, we demonstrate our method is more accurate than traditional calibration techniques with or without perturbations while also being real-time, marking a significant leap in the field of real-time multi-camera system calibration. The source code can be found at https://github.com/theICTlab/neural-recalibration
From data to action in flood forecasting leveraging graph neural networks and digital twin visualization
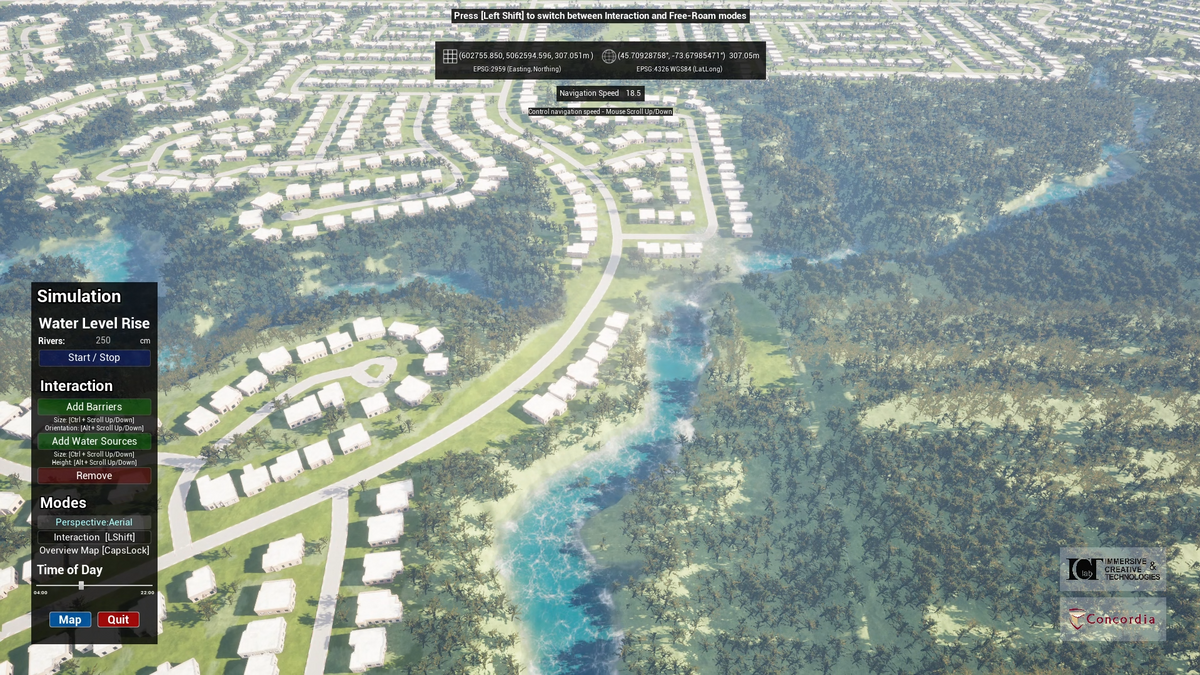
Abstract
Forecasting foods encompasses signifcant complexity due to the nonlinear nature of hydrological systems, which involve intricate interactions among precipitation, landscapes, river systems, and hydrological networks. Recent eforts in hydrology have aimed at predicting water fow, foods, and quality, yet most methodologies overlook the infuence of adjacent areas and lack advanced visualization for water level assessment. Our contribution is two-fold: frstly, we introduce a graph neural network model (LocalFLoodNet) equipped with a graph learning module to capture the interconnections of water systems and the connectivity between stations to predict future water levels. Secondly, we develop a simulation prototype ofering visual insights for decision-making in disaster prevention and policy-making. This prototype visualizes predicted water levels and facilitates data analysis using decades of historical information. Focusing on the Greater Montreal Area (GMA), particularly Terrebonne, Quebec, Canada, we apply LocalFLoodNet and prototype to demonstrate a comprehensive method for assessing food impacts. By utilizing a digital twin of Terrebonne, our simulation tool allows users to interactively modify the landscape and simulate various food scenarios, thereby providing valuable insights into preventive strategies. This research aims to enhance water level prediction and evaluation of preventive measures, setting a benchmark for similar applications across diferent geographic areas.
HydroVision: LiDAR-Guided Hydrometric Prediction with Vision Transformers and Hybrid Graph Learning
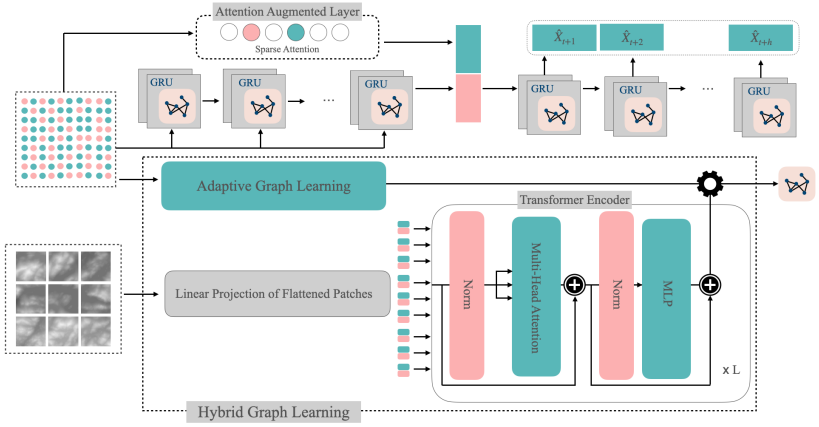
Abstract
Hydrometric forecasting is crucial for managing water resources, flood prediction, and environmental protection. Water stations are interconnected, and this connectivity influences the measurements at other stations. However, the dynamic and implicit nature of water flow paths makes it challenging to extract a priori knowledge of the connectivity structure. We hypothesize that terrain elevation significantly affects flow and connectivity. To incorporate this, we use LiDAR terrain elevation data encoded through a Vision Transformer (ViT). The ViT, which has demonstrated excellent performance in image classification by directly applying transformers to sequences of image patches, efficiently captures spatial features of terrain elevation. To account for both spatial and temporal features, we employ GRU blocks enhanced with graph convolution, a method widely used in the literature. We propose a hybrid graph learning structure that combines static and dynamic graph learning. A static graph, derived from transformer-encoded LiDAR data, captures terrain elevation relationships, while a dynamic graph adapts to temporal changes, improving the overall graph representation. We apply graph convolution in two layers through these static and dynamic graphs. Our method makes daily predictions up to 12 days ahead. Empirical results from multiple water stations in Quebec demonstrate that our method significantly reduces prediction error by an average of 10\% across all days, with greater improvements for longer forecasting horizons.
Transductive meta‑learning with enhanced feature ensemble for few‑shot semantic segmentation
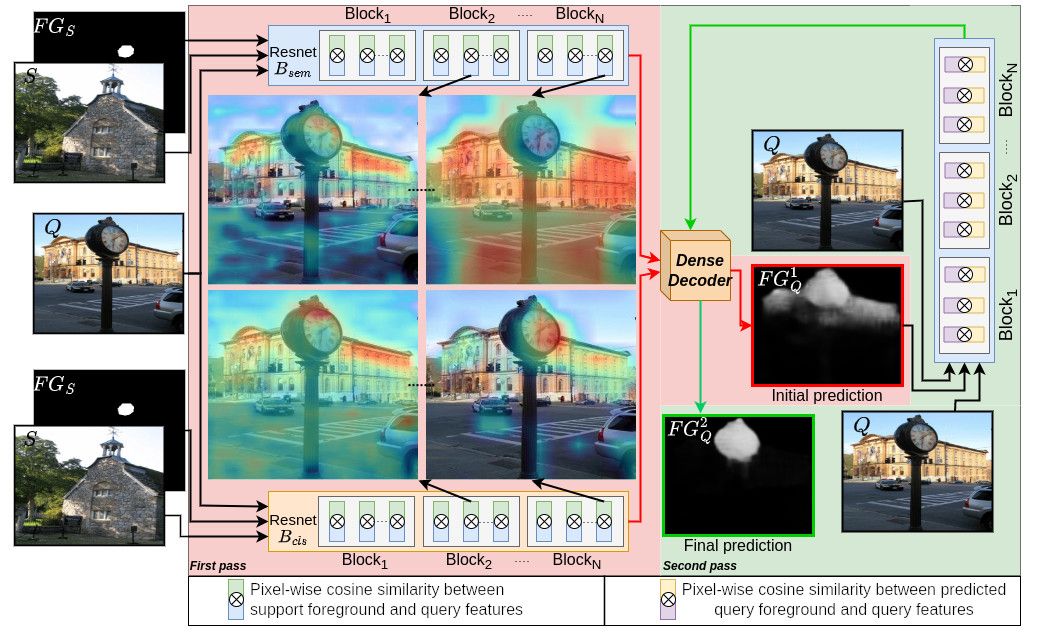
Abstract
This paper addresses few-shot semantic segmentation and proposes a novel transductive end-to-end method that overcomes three key problems afecting performance. First, we present a novel ensemble of visual features learned from pretrained classifcation and semantic segmentation networks with the same architecture. Our approach leverages the varying discriminative power of these networks, resulting in rich and diverse visual features that are more informative than a pretrained classifcation backbone that is not optimized for dense pixel-wise classifcation tasks used in most state-ofthe-art methods. Secondly, the pretrained semantic segmentation network serves as a base class extractor, which efectively mitigates false positives that occur during inference time and are caused by base objects other than the object of interest. Thirdly, a two-step segmentation approach using transductive meta-learning is presented to address the episodes with poor similarity between the support and query images. The proposed transductive meta-learning method addresses the prediction by frst learning the relationship between labeled and unlabeled data points with matching support foreground to query features (intra-class similarity) and then applying this knowledge to predict on the unlabeled query image (intra-object similarity), which simultaneously learns propagation and false positive suppression. To evaluate our method, we performed experiments on benchmark datasets, and the results demonstrate signifcant improvement with minimal trainable parameters of 2.98M. Specifcally, using Resnet-101, we achieve state-of-the-art performance for both 1-shot and 5-shot Pascal-5i, as well as for 1-shot and 5-shot COCO-20i.
Analysis of Hand Movement and Head Orientation in Hierarchical Menu Selection in Immersive AR
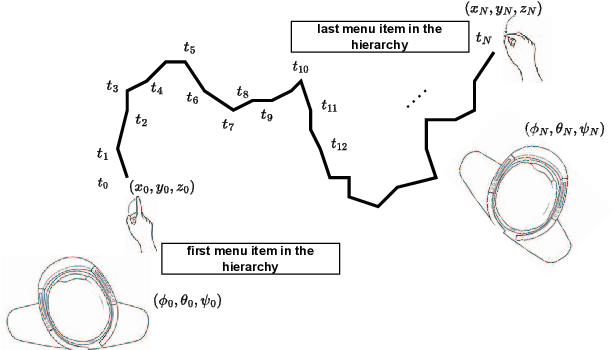
Abstract
Immersive Augmented Reality (AR) has become pervasive across multiple domains, ranging from medicine and education to interior design, and other fields. Leading technology giants like Apple, Meta, and Microsoft have introduced their proprietary Head Mounted Displays (HMD), joining the competitive market. This technology offers users an immersive experience by superimposing virtual 3D content onto real-world objects, allowing for various interactions and input modalities. Numerous Graphical User Interfaces (GUIs) have also been devised for immersive AR, integrating with input modalities such as hand gesture, head pointing, and voice commands. Since the most favored interaction method in immersive AR involves the interplay between hand gesture and head pointing, our research aims to analyze the workload exerted on users during hand gesture-head pointing interactions. For instance, a hierarchical menu selection task relies on both hand gesture (for item selection or click) and head pointing (to navigate the cursor). The degree of reliance on each input modality affects the user’s workload. We applied both objective and subjective means to assess the physical workload. Two user studies were conducted, from which we derived a unified metric to evaluate the interdependence of hand and head in immersive AR. A significant correlation was discovered between the metric and both objective and subjective workload assessments. Our findings provide insights for AR designers, suggesting the combined use of head pointing and hand gesture when creating hierarchical menu selection interfaces in immersive AR.
TransGlow: Attention-augmented Transduction model based on Graph Neural Networks for Water Flow Forecasting
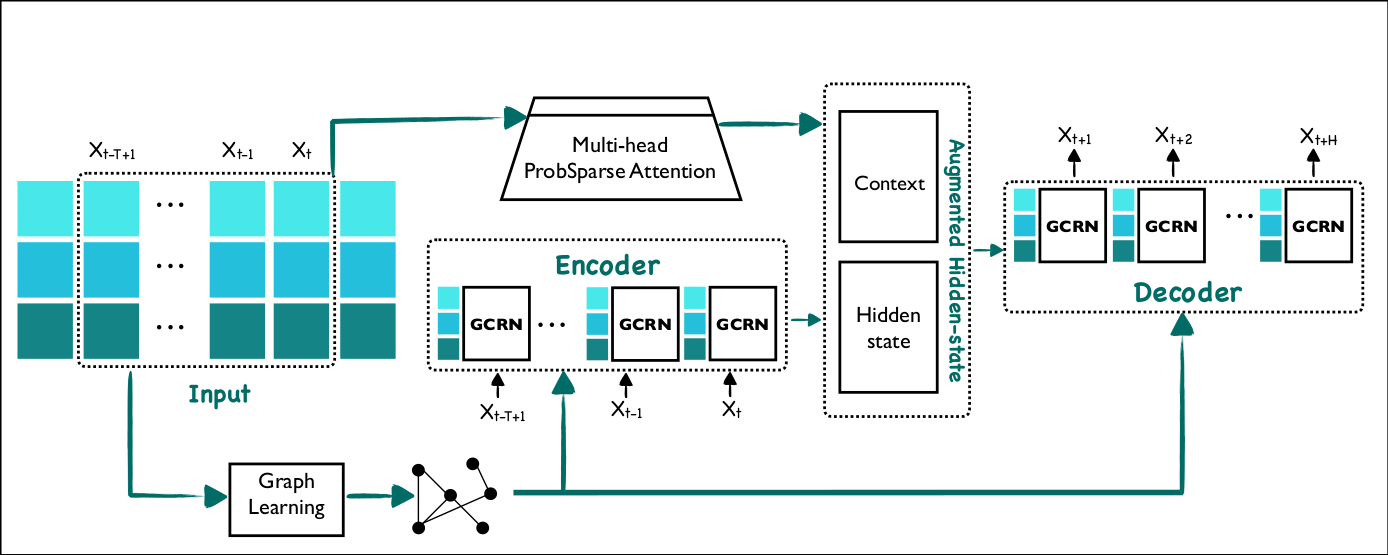
Abstract
The hydrometric prediction of water quantity is useful for a variety of applications, including water management, flood forecasting, and flood control. However, the task is difficult due to the dynamic nature and limited data of water systems. Highly interconnected water systems can significantly affect hydrometric forecasting. Consequently, it is crucial to develop models that represent the relationships between other system components. In recent years, numerous hydrological applications have been studied, including streamflow prediction, flood forecasting, and water quality prediction. Existing methods are unable to model the influence of adjacent regions between pairs of variables. In this paper, we propose a spatiotemporal forecasting model that augments the hidden state in Graph Convolution Recurrent Neural Network (GCRN) encoder-decoder using an efficient version of the attention mechanism. The attention layer allows the decoder to access different parts of the input sequence selectively. Since water systems are interconnected and the connectivity information between the stations is implicit, the proposed model leverages a graph learning module to extract a sparse graph adjacency matrix adaptively based on the data. Spatiotemporal forecasting relies on historical data. In some regions, however, historical data may be limited or incomplete, making it difficult to accurately predict future water conditions. Further, we present a new benchmark dataset of water flow from a network of Canadian stations on rivers, streams, and lakes. Experimental results demonstrate that our proposed model TransGlow significantly outperforms baseline methods by a wide margin.
Strategic Incorporation of Synthetic Data for Performance Enhancement in Deep Learning: A Case Study on Object Tracking Tasks
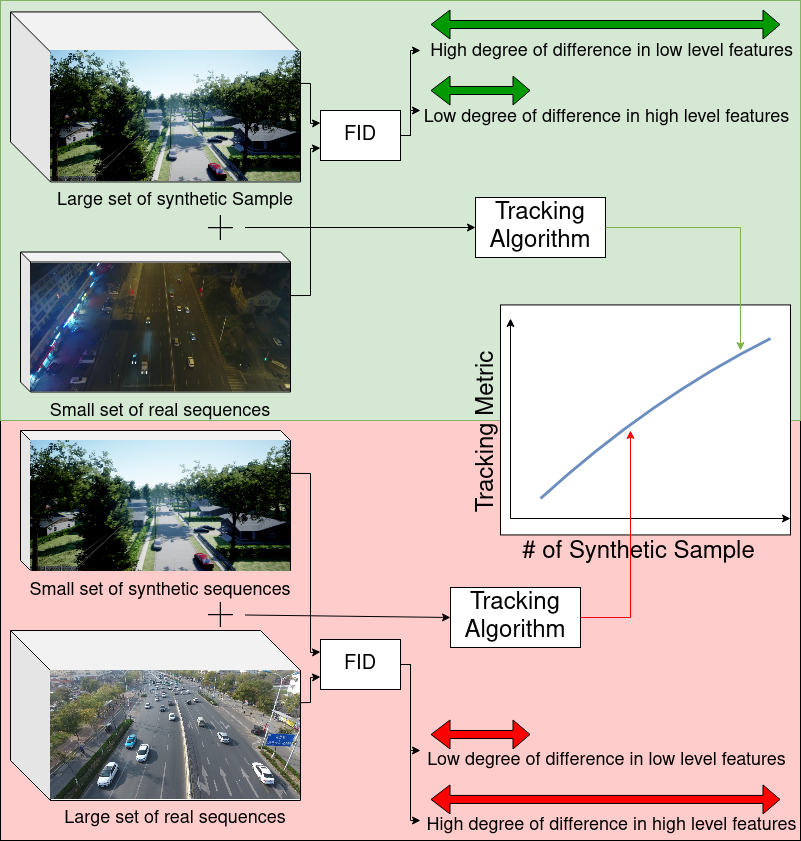
Abstract
Obtaining training data for machine learning models can be challenging. Capturing or gathering the data, followed by its manual labelling, is an expensive and time-consuming process. In cases where there are no publicly accessible datasets, this can significantly hinder progress. In this paper, we analyze the similarity between synthetic and real data. While focusing on an object tracking task, we investigate the quantitative improvement influenced by the concentration of the synthetic data and the variation in the distribution of training samples induced by it. Through examination of three well-known benchmarks, we reveal guidelines that lead to performance gain. We quantify the minimum variation required and demonstrate its efficacy on prominent object-tracking neural network architecture.
Tracking and Identification of Ice Hockey Players
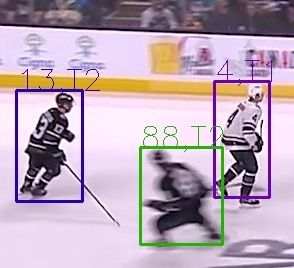
Abstract
Due to the rapid movement of players, ice hockey is a high-speed sport that poses significant challenges for player tracking. In this paper, we present a comprehensive framework for player identification and tracking in ice hockey games, utilising deep neural networks trained on actual gameplay data. Player detection, identification, and tracking are the three main components of our architecture. The player detection component detects individuals in an image sequence using a region proposal technique. The player identification component makes use of a text detector model that performs character recognition on regions containing text detected by a scene text recognition model, enabling us to resolve ambiguities caused by players from the same squad having similar appearances. After identifying the players, a visual multi-object tracking model is used to track their movements throughout the game. Experiments conducted with data collected from actual ice hockey games demonstrate the viability of our proposed framework for tracking and identifying players in real-world settings. Our framework achieves an average precision (AP) of 67.3 and a Multiple Object Tracking Accuracy (MOTA) of 80.2 for player detection and tracking, respectively. In addition, our team identification and player number identification accuracy is 82.39% and 87.19%, respectively. Overall, our framework is a significant advancement in the field of player tracking and identification in ice hockey, utilising cutting-edge deep learning techniques to achieve high accuracy and robustness in the face of complex and fast-paced gameplay. Our framework has the potential to be applied in a variety of applications, including sports analysis, player tracking, and team performance evaluation. Further enhancements can be made to address the challenges posed by complex and cluttered environments and enhance the system's precision.
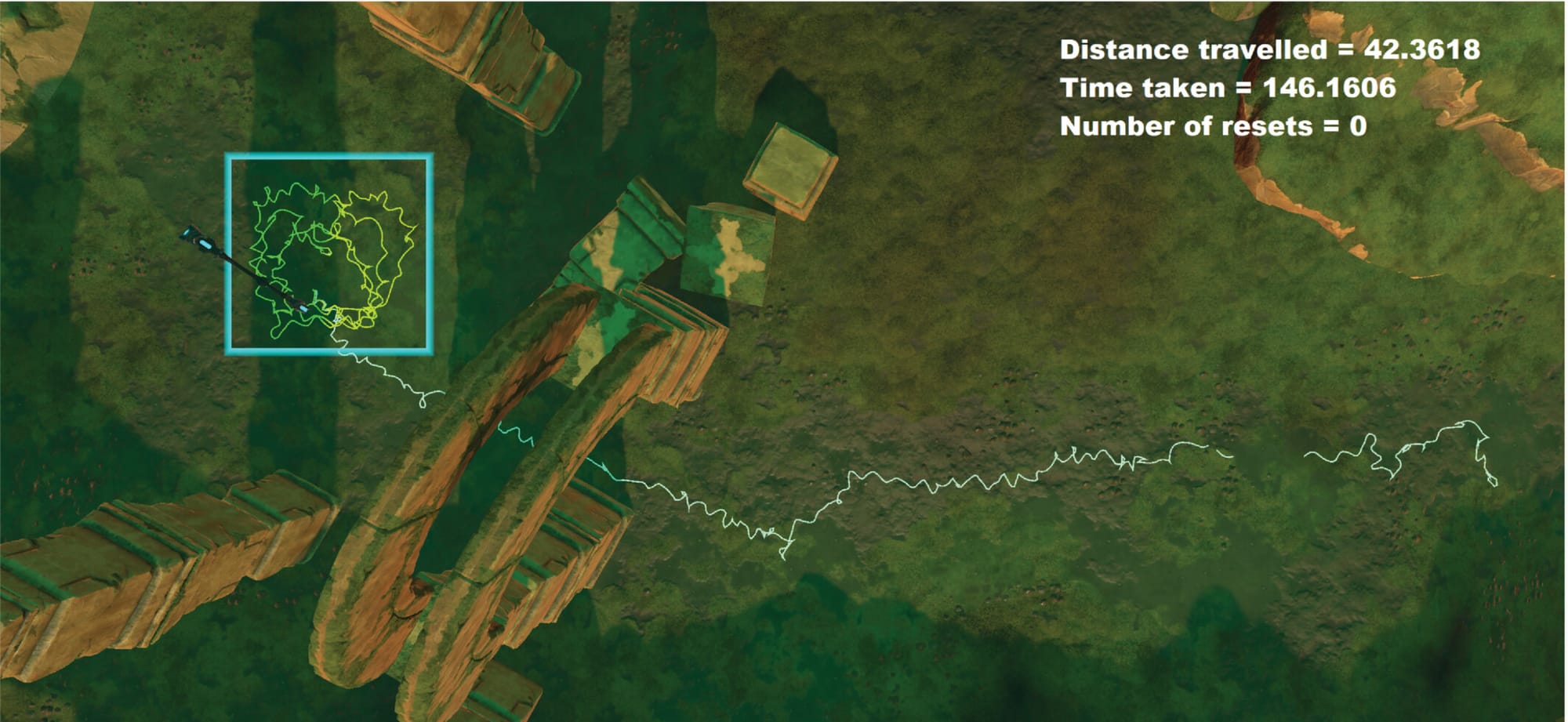
Enabling Saccadic Redirection Through Real-time Saccade Prediction

Abstract
Modern Redirected Walking (RDW) techniques significantly outperform classical solutions. Nevertheless, they are often limited by their heavy reliance on eye-tracking hardware embedded within the VR headset to reveal redirection opportunities. We propose a novel RDW technique that leverages the temporary blindness induced due to saccades for redirection. However, unlike the state-of-the-art, our approach does not impose additional eye-tracking hardware requirements. Instead, SaccadeNet, a deep neural network, is trained on head rotation data to predict saccades in real-time during an apparent head rotation. Rigid transformations are then applied to the virtual environment for redirection during the onset duration of these saccades. However, SaccadeNet is only effective when combined with a moderate cognitive workload that elicits repeated head rotations. We present three user studies. The relationship between head and gaze directions is confirmed in the first user study, followed by the training data collection in our second user study. Then, after some fine-tuning experiments, the performance of our RDW technique is evaluated in a third user study. Finally, we present the results demonstrating the efficacy of our approach. It allowed users to walk up a straight virtual distance of at least 38 meters from within a 3.5x3.5m2 of the physical tracked space. Moreover, our system unlocks saccadic redirection on widely used consumer-grade hardware without eye-tracking.
Tractable Large-Scale Deep Reinforcement Learning
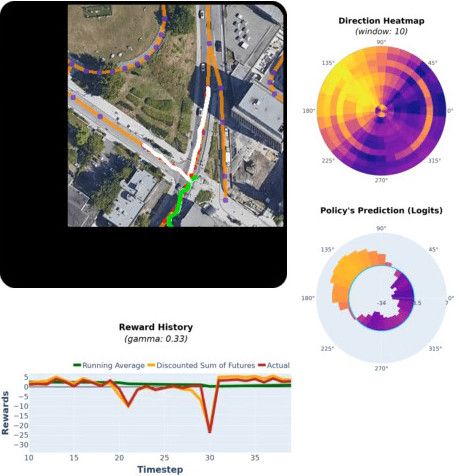
Abstract
Reinforcement learning (RL) has emerged as one of the most promising and powerful techniques in deep learning. The training of intelligent agents requires a myriad of training examples which imposes a substantial computational cost. Consequently, RL is seldom applied to real-world problems and historically has been limited to computer vision tasks, similar to supervised learning. This work proposes an RL framework for complex, partially observable, large-scale environments. We introduce novel techniques for tractable training on commodity GPUs, and significantly reduce computational costs. Furthermore, we present a self-supervised loss that improves the learning stability in applications with a long-time horizon, shortening the training time. We demonstrate the effectiveness of the proposed solution in the application of road extraction from high-resolution satellite images. We present experiments on satellite images of fifteen cities that demonstrate comparable performance to state-of-the-art methods. To the best of our knowledge, this is the first time RL has been applied for extracting road networks.
Managing real world and virtual motion
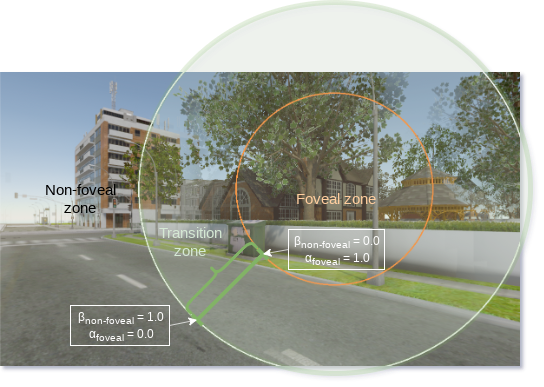
Abstract
Navigation of a virtual environment (VE) can mean navigating a VE that is spatially larger than the available Physical Tracked Space (PTS). Accordingly, the concept of redirected walking was introduced in order to provide a more natural way of navigating a VE, albeit with many restrictions on the shape and size of the physical and virtual spaces. However, prior art techniques have limitations such as negatively impacting the sense of immersion of the user, motion sickness, or forcing the user to look away by stimulating major saccades. Accordingly, the inventors have established a novel technique which overcomes these limitations. The technique is based on the psychological phenomenon of inattentional blindness allowing for re-directed walking without requiring the triggering major saccades in the users, complex expensive systems, etc.
Analysis of Error Rate in Hierarchical Menu Selection in Immersive Augmented Reality
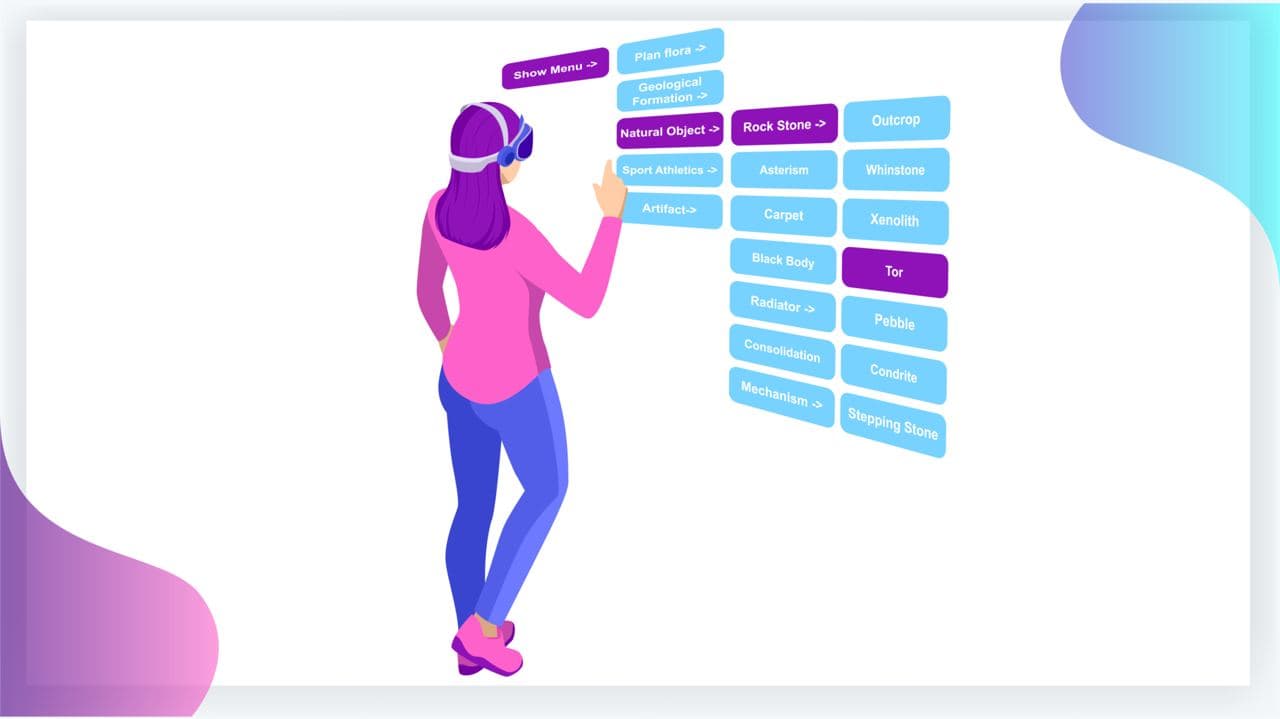
Abstract
The emergence of new immersive AR/VR headsets recently resulted in major improvements in hand-gesture-based user interfaces. Devices such as MS HoloLens II and Oculus Quest II support hand-gestures. Although using hand-gestures increases the sense of presence and ease of natural interactions, it has been shown that hand-gestures require extensive physical activity. Furthermore, it has been shown that the error rate in hierarchical menu selection is much higher when using hand-gestures than when using a desktop environment or the controllers. Therefore, assessing the difficulty of a hierarchical menu design when using hand-gestures and gaze for menu selection will enable UI designers to develop more effective user interfaces. In this work, we provide a validated index for estimating the hierarchical menu selection error using hand-gesture and head-gaze as input modalities. The index is informed by cognitive WAIS data gathered from participants, which measures subjective cognitive performance. The proposed index is the result of a user study that includes hundreds of hierarchical menu selections using MS HoloLens, and is validated against the data of a group of different participants. The results demonstrate that the index can successfully capture the trend of the users' errors in selecting the hierarchical menu items in immersive environments.
Motion Estimation for Large Displacements and Deformations

Abstract
Large displacement optical flow is an integral part of many computer vision tasks. Variational optical flow techniques based on a coarse-to-fine scheme interpolate sparse matches and locally optimize an energy model conditioned on colour, gradient and smoothness, making them sensitive to noise in the sparse matches, deformations, and arbitrarily large displacements. This paper addresses this problem and presents HybridFlow, a variational motion estimation framework for large displacements and deformations. A multi-scale hybrid matching approach is performed on the image pairs. Coarse-scale clusters formed by classifying pixels according to their feature descriptors are matched using the clusters' context descriptors. We apply a multi-scale graph matching on the finer-scale superpixels contained within each matched pair of coarse-scale clusters. Small clusters that cannot be further subdivided are matched using localized feature matching. Together, these initial matches form the flow, which is propagated by an edge-preserving interpolation and variational refinement. Our approach does not require training and is robust to substantial displacements and rigid and non-rigid transformations due to motion in the scene, making it ideal for large-scale imagery such as Wide-Area Motion Imagery (WAMI). More notably, HybridFlow works on directed graphs of arbitrary topology representing perceptual groups, which improves motion estimation in the presence of significant deformations. We demonstrate HybridFlow's superior performance to state-of-the-art variational techniques on two benchmark datasets and report comparable results with state-of-the-art deep-learning-based techniques.
Unsupervised Structure-Consistent Image-to-Image Translation

Abstract
The Swapping Autoencoder achieved state-of-the-art performance in deep image manipulation and image-to-image translation. We improve this work by introducing a simple yet effective auxiliary module based on gradient reversal layers. The auxiliary module's loss forces the generator to learn to reconstruct an image with an all-zero texture code, encouraging better disentanglement between the structure and texture information. The proposed attribute-based transfer method enables refined control in style transfer while preserving structural information without using a semantic mask. To manipulate an image, we encode both the geometry of the objects and the general style of the input images into two latent codes with an additional constraint that enforces structure consistency. Moreover, due to the auxiliary loss, training time is significantly reduced. The superiority of the proposed model is demonstrated in complex domains such as satellite images where state-of-the-art are known to fail. Lastly, we show that our model improves the quality metrics for a wide range of datasets while achieving comparable results with multi-modal image generation techniques.
Adaptive Memory Management for Video Object Segmentation
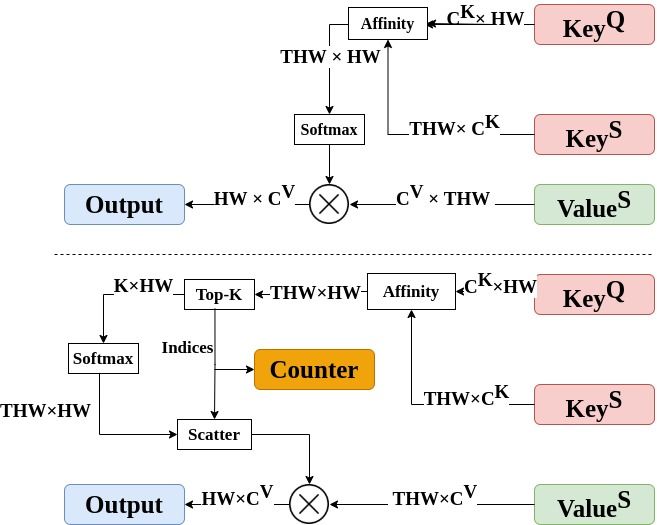
Abstract
Matching-based networks have achieved state-of-the-art performance for video object segmentation (VOS) tasks by storing every-k frames in an external memory bank for future inference. Storing the intermediate frames' predictions provides the network with richer cues for segmenting an object in the current frame. However, the size of the memory bank gradually increases with the length of the video, which slows down inference speed and makes it impractical to handle arbitrary length videos. This paper proposes an adaptive memory bank strategy for matching-based networks for semi-supervised video object segmentation (VOS) that can handle videos of arbitrary length by discarding obsolete features. Features are indexed based on their importance in the segmentation of the objects in previous frames. Based on the index, we discard unimportant features to accommodate new features. We present our experiments on DAVIS 2016, DAVIS 2017, and Youtube-VOS that demonstrate that our method outperforms state-of-the-art that employ first-and-latest strategy with fixed-sized memory banks and achieves comparable performance to the every-k strategy with increasing-sized memory banks. Furthermore, experiments show that our method increases inference speed by up to 80% over the every-k and 35% over first-and-latest strategies.
Simpler is better: Multilevel Abstraction with Graph Convolutional Recurrent Neural Network Cells for Traffic Prediction
Abstract
In recent years, graph neural networks (GNNs) combined with variants of recurrent neural networks (RNNs) have reached state-of-the-art performance in spatiotemporal forecasting tasks. This is particularly the case for traffic forecasting, where GNN models use the graph structure of road networks to account for spatial correlation between links and nodes. Recent solutions are either based on complex graph operations or avoiding predefined graphs. This paper proposes a new sequence-to-sequence architecture to extract the spatiotemporal correlation at multiple levels of abstraction using GNN-RNN cells with sparse architecture to decrease training time compared to more complex designs. Encoding the same input sequence through multiple encoders, with an incremental increase in encoder layers, enables the network to learn general and detailed information through multilevel abstraction. We further present a new benchmark dataset of street-level segment traffic data from Montreal, Canada. Unlike highways, urban road segments are cyclic and characterized by complicated spatial dependencies. Experimental results on the METR-LA benchmark highway and our MSLTD street-level segment datasets demonstrate that our model improves performance by more than 7% for one-hour prediction compared to the baseline methods while reducing computing resource requirements by more than half compared to other competing methods.
Predicting Surface Reflectance Properties of Outdoor Scenes Under Unknown Natural Illumination

Abstract
Estimating and modelling the appearance of an object under outdoor illumination conditions is a complex process. Although there have been several studies on illumination estimation and relighting, very few of them focus on estimating the reflectance properties of outdoor objects and scenes. This paper addresses this problem and proposes a complete framework to predict surface reflectance properties of outdoor scenes under unknown natural illumination. Uniquely, we recast the problem into its two constituent components involving the BRDF incoming light and outgoing view directions: (i) surface points' radiance captured in the images, and outgoing view directions are aggregated and encoded into reflectance maps, and (ii) a neural network trained on reflectance maps of renders of a unit sphere under arbitrary light directions infers a low-parameter reflection model representing the reflectance properties at each surface in the scene. Our model is based on a combination of phenomenological and physics-based scattering models and can relight the scenes from novel viewpoints. We present experiments that show that rendering with the predicted reflectance properties results in a visually similar appearance to using textures that cannot otherwise be disentangled from the reflectance properties.
Multi-view Gradient Consistency for SVBRDF Estimation of Complex Scenes under Natural Illumination

Abstract
This paper presents a process for estimating the spatially varying surface reflectance of complex scenes observed under natural illumination. In contrast to previous methods, our process is not limited to scenes viewed under controlled lighting conditions but can handle complex indoor and outdoor scenes viewed under arbitrary illumination conditions. An end-to-end process uses a model of the scene's geometry and several images capturing the scene's surfaces from arbitrary viewpoints and under various natural illumination conditions. We develop a differentiable path tracer that leverages least-square conformal mapping for handling multiple disjoint objects appearing in the scene. We follow a two-step optimization process and introduce a multi-view gradient consistency loss which results in up to 30-50% improvement in the image reconstruction loss and can further achieve better disentanglement of the diffuse and specular BRDFs compared to other state-of-the-art. We demonstrate the process in real-world indoor and outdoor scenes from images in the wild and show that we can produce realistic renders consistent with actual images using the estimated reflectance properties. Experiments show that our technique produces realistic results for arbitrary outdoor scenes with complex geometry. The source code is publicly available at: https://gitlab.com/alen.joy/multi-view-gradient-consistency-for-svbrdf-estimation-of-complex-scenes-under-natural-illumination
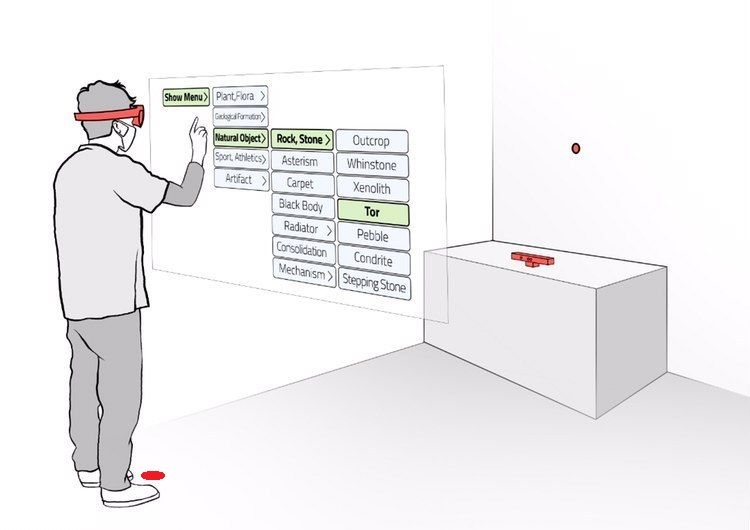
Predicting Human Performance in Vertical Hierarchical Menu Selection in Immersive AR Using Hand-gesture and Head-gaze
Abstract
There are currently limited guidelines on designing user interfaces (UI) for immersive augmented reality (AR) applications. Designers must reflect on their experience designing UI for desktop and mobile applications and conjecture how a UI will influence AR users' performance. In this work, we introduce a predictive model for determining users' performance for a target UI without the subsequent involvement of participants in user studies. The model is trained on participants' responses to objective performance measures such as consumed endurance (CE) and pointing time (PT) using hierarchical drop-down menus. Large variability in the depth and context of the menus is ensured by randomly and dynamically creating the hierarchical drop-down menus and associated user tasks from words contained in the lexical database WordNet. Subjective performance bias is reduced by incorporating the users' non-verbal standard performance WAIS-IV during the model training. The semantic information of the menu is encoded using the Universal Sentence Encoder. We present the results of a user study that demonstrates that the proposed predictive model achieves high accuracy in predicting the CE on hierarchical menus of users with various cognitive abilities. To the best of our knowledge, this is the first work on predicting CE in designing UI for immersive AR applications.
End-to-End Multi-View Structure-from-Motion with Hypercorrelation Volumes
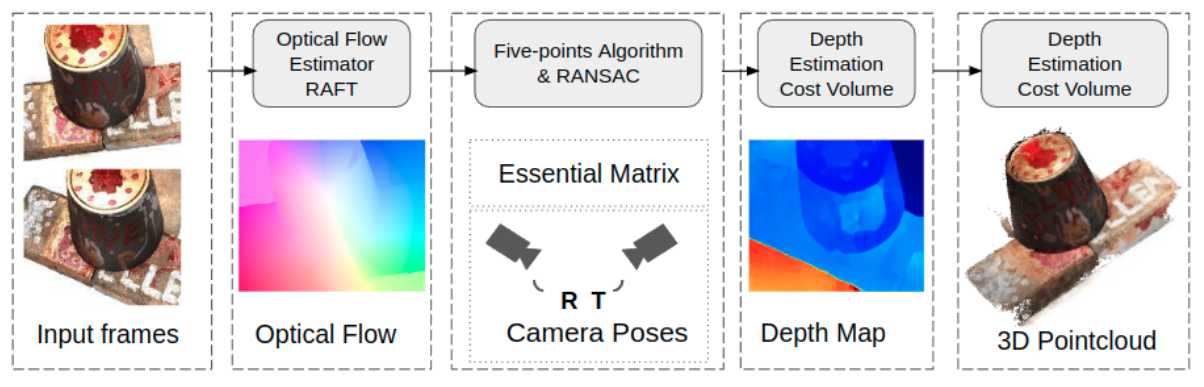
Abstract
Image-based 3D reconstruction is one of the most important tasks in Computer Vision with many solutions proposed over the last few decades. The objective is to extract metric information i.e. the geometry of scene objects directly from images. These can then be used in a wide range of applications such as film, games, virtual reality, etc. Recently, deep learning techniques have been proposed to tackle this problem. They rely on training on vast amounts of data to learn to associate features between images through deep convolutional neural networks and have been shown to outperform traditional procedural techniques. In this paper, we improve on the state-of-the-art two-view structure-from-motion(SfM) approach of Wang et al. [11] by incorporating 4D correlation volume for more accurate feature matching and reconstruction. Furthermore, we extend it to the general multi-view case and evaluate it on the complex benchmark dataset DTU [4]. Quantitative evaluations and comparisons with state-of-the-art multi-view 3D reconstruction methods demonstrate its superiority in terms of the accuracy of reconstructions.
Semantic Segmentation from Remote Sensor Data and the Exploitation of Latent Learning for Classification of Auxiliary Tasks
Abstract
In this paper we address three different aspects of semantic segmentation from remote sensor data using deep neural networks. Firstly, we focus on the semantic segmentation of buildings from remote sensor data and propose ICT-Net: a novel network with the underlying architecture of a fully convolutional network, infused with feature re-calibrated Dense blocks at each layer. Secondly, as the building classification is typically the first step of the reconstruction process, we investigate the relationship of the classification accuracy to the reconstruction accuracy. Finally, we present the simple yet compelling concept of latent learning and the implications it carries within the context of deep learning. We posit that a network trained on a primary task (i.e. building classification) is unintentionally learning about auxiliary tasks (e.g. the classification of road, tree, etc) which are complementary to the primary task. We present the results of our experiments and explain how knowledge about auxiliary and complementary tasks - for which the network was never trained - can be retrieved and utilized for further classification. The source code and supplemental material is publicly available at http://www.theICTlab.org/lp/2020ICTNet/
EyeTAP: A Novel Technique using Voice Inputs to Address the Midas Touch Problem for Gaze-based Interactions
Abstract
One of the main challenges of gaze-based interactions is the ability to distinguish normal eye function from a deliberate interaction with the computer system, commonly referred to as "Midas touch". In this paper we propose EyeTAP (Eye tracking point-and-select by Targeted Acoustic Pulse) a contact-free multimodal interaction method for point-and-select tasks. We evaluated the prototype in four user studies with 33 participants and found that EyeTAP is applicable in the presence of ambient noise, results in a faster movement time, and faster task completion time, and has a lower cognitive workload than voice recognition. In addition, although EyeTAP did not generally outperform the dwell-time method, it did have a lower error rate than the dwell-time in one of our experiments. Our study shows that EyeTAP would be useful for users for whom physical movements are restricted or not possible due to a disability or in scenarios where contact-free interactions are necessary. Furthermore, EyeTAP has no specific requirements in terms of user interface design and therefore it can be easily integrated into existing systems.
IDEA: Index of Difficulty for Eye tracking Applications An Analysis Model for Target Selection Tasks
Abstract
Fitts' law is a prediction model to measure the difficulty level of target selection for pointing devices. However, emerging devices and interaction techniques require more flexible parameters to adopt the original Fitts' law to new circumstances and case scenarios. We propose Index of Difficulty for Eye tracking Applications (IDEA) which integrates Fitts' law with users' feedback from the NASA TLX to measure the difficulty of target selection. The COVID-19 pandemic has shown the necessity of contact-free interactions on public and shared devices, thus in this work, we aim to propose a model for evaluating contact-free interaction techniques, which can accurately measure the difficulty of eye tracking applications and can be adapted to children, users with disabilities, and elderly without requiring the acquisition of physiological sensory data. We tested the IDEA model using data from a three-part user study with 33 participants which compared two eye tracking selection techniques, dwell-time, and a multi-modal eye tracking technique using voice commands.
Dynamic Foveated Rendering for Redirected Walking in Virtual Reality
Abstract
In this work we present a novel technique for redirected walking in VR based on the psychological phenomenon of inattentional blindness. Based on the user's visual fixation points we divide the user's field of view (FoV) into zones. Spatially-varying rotations are then applied according to the zone's importance and are rendered using foveated rendering. Our technique is real-time and applicable to small and large physical spaces. Furthermore, the proposed technique does not require the use of stimulated saccades [1] but rather takes advantage of naturally occurring major and minor saccades and blinks to perform a complete refresh of the framebuffer. We performed extensive testing with the analysis of the results presented from three user studies conducted for the evaluation. Results show that the proposed technique is indeed viable and users were able to walk straight for more than 100m in VE within the confines of 4x4m2 of PTS.
FELiX: Fixation-based Eye Fatigue Load Index A Multi-factor Measure for Gaze-based Interactions
Abstract
Eye fatigue is a common challenge in eye tracking applications caused by physical and/or mental triggers. Its impact should be analyzed in eye tracking applications, especially for the dwell-time method. As emerging interaction techniques become more sophisticated, their impacts should be analyzed based on various aspects. We propose a novel compound measure for gaze-based interaction techniques that integrates subjective NASA TLX scores with objective measurements of eye movement fixation points. The measure includes two variations depending on the importance of (a) performance, and (b) accuracy, for measuring potential eye fatigue for eye tracking interactions. These variations enable researchers to compare eye tracking techniques on different criteria. We evaluated our measure in two user studies with 33 participants and report on the results of comparing dwell-time and gaze-based selection using voice recognition techniques.
Inattentional Blindness for Redirected Walking Using Dynamic Foveated Rendering
Abstract
Redirected walking is a Virtual Reality (VR) locomotion technique which enables users to navigate virtual environments (VEs) that are spatially larger than the available physical tracked space. In this work we present a novel technique for redirected walking in VR based on the psychological phenomenon of inattentional blindness. Based on the user's visual fixation points we divide the user's view into zones. Spatially-varying rotations are applied according to the zone's importance and are rendered using foveated rendering. Our technique is real-time and applicable to small and large physical spaces. Furthermore, the proposed technique does not require the use of stimulated saccades but rather takes advantage of naturally occurring saccades and blinks for a complete refresh of the framebuffer. We performed extensive testing and present the analysis of the results of three user studies conducted for the evaluation.
Portal to knowledge: A Virtual Library Using Markerless Augmented Reality System for Mobile Device
Abstract
Since exceedingly efficient hand-held devices became readily available to the world, while not being a relatively recent topic, Augmented Reality (AR) has rapidly become one of the most prominent research subjects. These robust devices could compute copious amounts of data in a mere blink of an eye. Making it feasible to overlap computer generated, interactive, graphics over the real world images in real-time to enhance the comprehensive immersive experience of the user. In this paper, we present a novel mobile application which allows the users to explore and interact with a virtual library in their physical space using marker-less AR. Digital versions of books are represented by 3D book objects on bookcases similar to an actual library. Using an in-app gaze controller, the user's gaze is tracked and mapped into the virtual library. This allows the users to select (via gaze) a digital version of any book and download it for their perusal. To complement the immersive user experience, a continuity is maintained using the concept of Portals while making any transition from AR to immersive VR or vice-versa, corresponding to transitioning from a "physical" to a virtual space. The use of portals makes these transitions simple and seamless for the user. The presented application was implemented using Google AR Core SDK and Unity 3D, and will serve as a handy tool to spawn a virtual library anytime and anywhere, giving the user an imminent mixed sense of being in an actual traditional library while having the digital version of any book on the go.
Large-scale Urban Reconstruction with Tensor Clustering and Global Boundary Refinement
Abstract
Accurate and efficient methods for large-scale urban reconstruction are of significant importance to the computer vision and computer graphics communities. Although rapid acquisition techniques such as airborne LiDAR have been around for many years, creating a useful and functional virtual environment from such data remains difficult and labor intensive. This is due largely to the necessity in present solutions for data dependent user defined parameters. In this paper we present a new solution for automatically converting large LiDAR data pointcloud into simplified polygonal 3D models. The data is first divided into smaller components which are processed independently and concurrently to extract various metrics about the points. Next, the extracted information is converted into tensors. A robust agglomerate clustering algorithm is proposed to segment the tensors into clusters representing geospatial objects e.g. roads, buildings, etc. Unlike previous methods, the proposed tensor clustering process has no data dependencies and does not require any user-defined parameter. The required parameters are adaptively computed assuming a Weibull distribution for similarity distances. Lastly, to extract boundaries from the clusters a new multi-stage boundary refinement process is developed by reformulating this extraction as a global optimization problem. We have extensively tested our methods on several pointcloud datasets of different resolutions which exhibit significant variability in geospatial characteristics e.g. ground surface inclination, building density, etc and the results are reported. The source code for both tensor clustering and global boundary refinement will be made publicly available with the publication on the author's website.
Visualizing and Interacting with Hierarchical Menus in Immersive Augmented Reality
Abstract
Graphical User Interfaces (GUIs) have long been used as a way to inform the user of the large number of available actions and options. GUIs in desktop applications traditionally appear in the form of two-dimensional hierarchical menus due to the limited screen real estate, the spatial restrictions imposed by the hardware e.g. 2D, and the available input modalities e.g. mouse/keyboard point-and-click, touch, dwell-time etc. In immersive Augmented Reality (AR), there are no such restrictions and the available input modalities are different (i.e. hand gestures, head pointing or voice recognition), yet the majority of the applications in AR still use the same type of GUIs as with desktop applications. In this paper we focus on identifying the most efficient combination of (hierarchical menu type, input modality) to use in immersive applications using AR headsets. We report on the results of a within-subjects study with 25 participants who performed a number of tasks using four combinations of the most popular hierarchical menu types with the most popular input modalities in AR, namely: (drop-down menu, hand gestures), (drop-down menu, voice), (radial menu, hand gestures), and (radial menu, head pointing). Results show that the majority of the participants (60%, 15) achieved a faster performance using the hierarchical radial menu with head pointing control. Furthermore, the participants clearly indicated the radial menu with head pointing control as the most preferred interaction technique due to the limited physical demand as opposed to the current de facto interaction technique in AR i.e. hand gestures, which after prolonged use becomes physically demanding leading to arm fatigue known as "Gorilla arms".
Delineation of Road Networks Using Deep Residual Neural Networks and Iterative Hough Transform
Abstract
In this paper we present a complete pipeline for extracting road network vector data from satellite RGB orthophotos of urban areas. Firstly, a network based on the SegNeXt architecture with a novel loss function is employed for the semantic segmentation of the roads. Results show that the proposed network produces on average better results than other state-of-the-art semantic segmentation techniques. Secondly, we propose a fast post-processing technique for vectorizing the rasterized segmentation result, removing erroneous lines, and refining the road network. The result is a set of vectors representing the road network. We have extensively tested the proposed pipeline and provide quantitative and qualitative comparisons with other state-of-the-art based on a number of known metrics.
On Building Classification from Remote Sensor Imagery Using Deep Neural Networks and the Relation Between Classification and Reconstruction Accuracy Using Border Localization as Proxy
Abstract
Convolutional neural networks have been shown to have a very high accuracy when applied to certain visual tasks and in particular semantic segmentation. In this paper we address the problem of semantic segmentation of buildings from remote sensor imagery. We present ICT-Net: a novel network with the underlying architecture of a fully convolutional network, infused with feature re-calibrated Dense blocks at each layer. Uniquely, the proposed network combines the localization accuracy and use of context of the U-Net network architecture, the compact internal representations and reduced feature redundancy of the Dense blocks, and the dynamic channel-wise feature re-weighting of the Squeeze-and-Excitation(SE) blocks. The proposed network has been tested on INRIA's benchmark dataset and is shown to outperform all other state-of-the-art by more than 1.5% on the Jaccard index. Furthermore, as the building classification is typically the first step of the reconstruction process, in the latter part of the paper we investigate the relationship of the classification accuracy to the reconstruction accuracy. A comparative quantitative analysis of reconstruction accuracies corresponding to different classification accuracies confirms the strong correlation between the two. We present the results which show a consistent and considerable reduction in the reconstruction accuracy. The source code and supplemental material is publicly available at http://www.theICTlab.org/lp/2019ICTNet/
Evaluation of "The Seafarers": A Serious Game on Seaborne Trade in the Mediterranean Sea during the Classical period
Abstract
Throughout the history of the Mediterranean region, seafaring and trading played a significant role in the interaction between the cultures and people in the area. In order to engage the general public in learning about maritime cultural heritage we have designed and developed a serious game incorporating geospatially analyzed data from open GIS archaeological maritime sources, and archaeological data resulting from shipwreck excavations. We present a second prototype of the seafaring serious game, and discuss the results of an evaluation which involved a large multi-site user study with participants from three continents. More specifically, we present the evaluation of "The Seafarers" a strategy-based game which integrates knowledge from multiple disciplines in order to educate the user through playing. A first prototype was reported in [34] where an expert-user evaluation of the usability and the effectiveness of the game in terms of the learning objectives was performed. In this paper, we present how the outcomes of the evaluation of the first prototype "The Seafarers - 1" by expert-users were used in the redesign and development of the game mechanics for the second prototype "The Seafarers-2". We then present our methodology for evaluating the game with respect to the game objective of engagement in learning about maritime cultural heritage, seafaring and trading in particular. Specifically, the evaluation was to test the hypothesis that game playing allows for more engaged learning thus improving longer-term knowledge retention. The evaluation was conducted in two phases and includes a pilot study, followed by a multi-site, multi-continent user-study involving a large number of participants. We analyze the results of the user evaluation and discuss the outcomes. This work is part of the EU-funded project iMareCulture and involves truly multi-continental, multi-institutional and multi-disciplinary cooperation - civil engineers and archaeologists from Cyprus, Human Computer Interaction (HCI) experts and Educationists from Bosnia and Herzegovina, Canada, and cultural sociologists and computer scientists from Canada.
Deep Autoencoders with Aggregated Residual Transformations for Urban Reconstruction from Remote Sensor Data
Abstract
In this work we investigate urban reconstruction and propose a complete and automatic framework for reconstructing urban areas from remote sensor data. Firstly, we address the complex problem of semantic labeling and propose a novel network architecture named SegNeXT which combines the strengths of deep-autoencoders with feed-forward links in generating smooth predictions and reducing the number of learning parameters, with the effectiveness which cardinality-enabled residual-based building blocks have shown in improving prediction accuracy and outperforming deeper/wider network architectures with a smaller number of learning parameters. The network is trained with benchmark datasets and the reported results show that it can provide at least similar and in some cases better classification than state-of-the-art. Secondly, we address the problem of urban reconstruction and propose a complete pipeline for automatically converting semantic labels into virtual representations of the urban areas. An agglomerative clustering is performed on the points according to their classification and results in a set of contiguous and disjoint clusters. Finally, each cluster is processed according to the class it belongs: tree clusters are substituted with procedural models, cars are replaced with simplified CAD models, buildings' boundaries are extruded to form 3D models, and road, low vegetation, and clutter clusters are triangulated and simplified. The result is a complete virtual representation of the urban area. The proposed framework has been extensively tested on large-scale benchmark datasets and the semantic labeling and reconstruction results are reported.
DeepCaustics: Classification and Removal of Caustics From Underwater Imagery
Abstract
Caustics are complex physical phenomena resulting from the projection of light rays being reflected or refracted by a curved surface. In this paper, we address the problem of classifying and removing caustics from images and propose a novel solution based on two convolutional neural networks: SalienceNet and DeepCaustics. Caustics result in changes in illumination that are continuous in nature; therefore, the first network is trained to produce a classification of caustics that is represented as a saliency map of the likelihood of caustics occurring at a pixel. In applications where caustic removal is essential, the second network is trained to generate a caustic-free image. It is extremely hard to generate real ground truth for caustics. We demonstrate how synthetic caustic data can be used for training in such cases, and then transfer the learning to real data. To the best of our knowledge, out of the handful of techniques that have been proposed, this is the first time that the complex problem of caustic removal has been reformulated and addressed as a classification and learning problem. This paper is motivated by the real-world challenges in underwater archaeology. IEEE
Single-shot Dense Reconstruction with Epic-flow
Abstract
In this paper we present a novel method for generating dense reconstructions by applying only structure-from-motion(SfM) on large-scale datasets without the need for multi-view stereo as a post-processing step. A state-of-the-art optical flow technique is used to generate dense matches. The matches are encoded such that verification for correctness becomes possible, and are stored in a database on-disk. The use of this out-of-core approach transfers the requirement for large memory space to disk, therefore allowing for the processing of even larger-scale datasets than before. We compare our approach with the state-of-the-art and present the results which verify our claims.
Underwater photogrammetry in very shallow waters: Main challenges and caustics effect removal
Abstract
In this paper, main challenges of underwater photogrammetry in shallow waters are described and analysed. The very short camera to object distance in such cases, as well as buoyancy issues, wave effects and turbidity of the waters are challenges to be resolved. Additionally, the major challenge of all, caustics, is addressed by a new approach for caustics removal (Forbes et al., 2018) which is applied in order to investigate its performance in terms of SfM-MVS and 3D reconstruction results. In the proposed approach the complex problem of removing caustics effects is addressed by classifying and then removing them from the images. We propose and test a novel solution based on two small and easily trainable Convolutional Neural Networks (CNNs). Real ground truth for caustics is not easily available. We show how a small set of synthetic data can be used to train the network and later transfer the le arning to real data with robustness to intra-class variation. The proposed solution results in caustic-free images which can be further used for other tasks as may be needed.
Reflecting on the Design Process for Virtual Reality Applications
Abstract
A reflective analysis on the experience of virtual environment (VE) design is presented focusing on the human-computer interaction (HCI) challenges presented by virtual reality (VR). HCI design guidelines were applied to development of two VRs, one in marine archaeology and the other in situation awareness simulation experiments. The impact of methods and HCI knowledge on the VR design process is analyzed, leading to proposals for presenting HCI and cognitive knowledge in the context of design trade-offs in the choice of VR design techniques. Problems reconciling VE and standard Graphical User Interface (GUI) design components are investigated. A trade-off framework for design options set against criteria for usability, efficient operation, realism, and presence is proposed. HCI-VR design advice and proposals for further research aimed towards improving human factor-related design in VEs are discussed.
Automatic 2D to stereoscopic video conversion for 3D TVS
Abstract
In this paper we present a novel technique for automatically converting 2D videos to stereoscopic. Uniquely, the proposed approach leverages the strengths of Deep Learning to address the complex problem of depth estimation from a single image. A Convolutional Neural Network is trained on input RGB images and their corresponding depths maps. We reformulate and simplify the process of generating the second camera's depth map and present how this can be used to render an anaglyph image. The anaglyph image was used for demonstration only because of the easy and wide availability of red/cyan glasses however, this does not limit the applicability of the proposed technique to other stereo forms. Finally, we present preliminary results and discuss the challenges.
Multi-label Pixelwise Classification for Reconstruction of Large-scale Urban Areas
Abstract
We present our distinct solution based on a convolutional neural network (CNN) for performing multi-label pixelwise classification and its application to large-scale urban reconstruction. A supervised learning approach is followed for training a 13-layer CNN using both LiDAR and satellite images. An empirical study has been conducted to determine the hyperparameters which result in the optimal performance of the CNN. Scale invariance is introduced by training the network on five different scales of the input and labeled data. This results in six pixelwise classifications for each different scale. An SVM is then trained to map the six pixelwise classifications into a single-label. Lastly, we refine boundary pixel labels using graph-cuts for maximum a-posteriori (MAP) estimation with Markov Random Field (MRF) priors. The resulting pixelwise classification is then used to accurately extract and reconstruct the buildings in large-scale urban areas. The proposed approach has been extensively tested and the results are reported.
Development and integration of digital technologies addressed to raise awareness and access to European underwater cultural heritage. An overview of the H2020 i-MARECULTURE project
Abstract
The Underwater Cultural Heritage (UCH) represents a vast historical and scientific resource that, often, is not accessible to the general public due the environment and depth where it is located. Digital technologies (Virtual Museums, Virtual Guides and Virtual Reconstruction of Cultural Heritage) provide a unique opportunity for digital accessibility to both scholars and general public, interested in having a better grasp of underwater sites and maritime archaeology. This paper presents the architecture and the first results of the Horizon 2020 i-MARECULTURE (Advanced VR, iMmersive Serious Games and Augmented REality as Tools to Raise Awareness and Access to European Underwater CULTURal heritage) project that aims to develop and integrate digital technologies for supporting the wide public in acquiring knowledge about UCH. A Virtual Reality (VR) system will be developed to allow users to visit the underwater sites through the use of Head Mounted Displays (HMDs) or digital holographic screens. Two serious games will be implemented for supporting the understanding of the ancient Mediterranean seafaring and the underwater archaeological excavations. An Augmented Reality (AR) system based on an underwater tablet will be developed to serve as virtual guide for divers that visit the underwater archaeological sites.
Automatic adjustment of stereoscopic content for long-range projections in outdoor areas
Abstract
Projecting stereoscopic content onto large general outdoor surfaces, say building facades, presents many challenges to be overcome, particularly when using red-cyan anaglyph stereo representation, so that as accurate as possible colour and depth perception can still be achieved. In this paper, we address the challenges relating to long-range projection mapping of stereoscopic content in outdoor areas and present a complete framework for the automatic adjustment of the content to compensate for any adverse projection surface behaviour. We formulate the problem of modeling the projection surface into one of simultaneous recovery of shape and appearance. Our system is composed of two standard fixed cameras, a long range fixed projector, and a roving video camera for multi-view capture. The overall computational framework comprises of four modules: calibration of a long-range vision system using the structure from motion technique, dense 3D reconstruction of projection surface from calibrated camera images, modeling the light behaviour of the projection surface using roving camera images and, iterative adjustment of the stereoscopic content. In addition to cleverly adapting some of the established computer vision techniques, the system design we present is distinct from previous work. The proposed framework has been tested in real-world applications with two non-trivial user experience studies and the results reported show considerable improvements in the quality of 3D depth and colour perceived by human participants.
A serious game for understanding ancient seafaring in the Mediterranean sea
Abstract
Commercial sea routes joining Europe with other cultures are vivid examples of cultural interaction. In this work, we present a serious game which aims to provide better insight and understanding of seaborne trade mechanisms and seafaring practices in the eastern Mediterranean during the Classical and Hellenistic periods. The game incorporates probabilistic geospatial analysis of possible ship routes through the re-use and spatial analysis from open GIS maritime, ocean, and weather data. These routes, along with naval engineering and sailing techniques from the period, are used as underlying information for the seafaring game. This work is part of the EU-funded project iMareCulture whose purpose is in raising the European identity awareness using maritime and underwater cultural interaction and exchange in the Mediterranean sea.
A long-range vision system for projection mapping of stereoscopic content in outdoor areas
Abstract
Spatial Augmented Reality, or its more commonly known name Projection Mapping (PM), is a projection technique which transforms a real-life object or scene into a surface for video projection (Raskar et al., 1998b). Although this technique has been pioneered and used by Disney since the seventies, it is in recent years that it has gained significant popularity due to the availability of specialized software which simplifies the otherwise cumbersome calibration process (Raskar et al., 1998a). Currently, PM is being widely used in advertising, marketing, cultural events, live performances, theater, etc as a way of enhancing an object/scene by superimposing visual content (Ridel et al., 2014). However, despite the wide availability of specialized software, several restrictions are still imposed on the type of objects/scenes on which PM can be applied. Most limitations are due to problems in handling objects/scenes with (a) complex reflectance properties and (b) low intensity or distinct colors. In this work, we address these limitations and present solutions for mitigating these problems. We present a complete framework for calibration, geometry acquisition and reconstruction, estimation of reflectance properties, and finally color compensation; all within the context of outdoor long-range PM of stereoscopic content. Using the proposed technique, the observed projections are as close as possible [constrained by hardware limitations] to the actual content being projected; therefore ensuring the perception of depth and immersion when viewed with stereo glasses. We have performed extensive experiments and the results are reported.
Navigation in virtual reality: Comparison of gaze-directed and pointing motion control
Abstract
We compared two locomotion techniques in an immersive CAVE-like display in order to determine which one promotes better performance in a wayfinding task. One method, commonly found in computer games, allows participants to steer through the 3D scene according to their gaze direction while the other uncouples the gaze direction from the direction of travel. In both cases tracked physical head movements determined the gaze direction. In order to provide a realistic scenario for comparing these methods we devised a task in which participants had to navigate to various houses of a virtual village that was previously seen on a map. The 2D coordinates of paths taken by participants were recorded together with their success rates in finding the targets, and the time taken to reach their destination. Participants showed better results with the pointing method of motion control, reaching the targets faster and with fewer errors. Results are interpreted with respect to the benefits afforded by large field of view displays.
Studying children's navigation in virtual reality
Abstract
Navigation in large-scale virtual environments is composed of locomotion and wayfinding. We compared two locomotion techniques in an immersive CAVE-like display in order to determine which one promotes better performance in children in a wayfinding task. A "treasure hunt" game scenario was devised in which participants had to navigate to various houses of a virtual village that was previously seen only on a map. The 2D coordinates of paths taken by participants were recorded together with their success rates in finding the targets, and the time taken to reach their destination. Children showed that although the pointing method allowed them better control in locomotion, neither method was preferred in terms of success rates and timing.
Project iMARECULTURE: Advanced VR, immersive serious games and augmented reality as tools to raise awareness and access to European underwater cultural heritage
Abstract
The project iMARECULTURE is focusing in raising European identity awareness using maritime and underwater cultural interaction and exchange in Mediterranean Sea. Commercial ship routes joining Europe with other cultures are vivid examples of cultural interaction, while shipwrecks and submerged sites, unreachable to wide public are excellent samples that can benefit from immersive technologies, augmented and virtual reality. The projects aim to bring inherently unreachable underwater cultural heritage within digital reach of the wide public using virtual visits and immersive technologies. Apart from reusing existing 3D data of underwater shipwrecks and sites, with respect to ethics, rights and licensing, to provide a personalized dry visit to a museum visitor or augmented reality to the diver, it also emphasizes on developing pre- and after- encounter of the digital or physical museum visitor. The former one is implemented exploiting geospatial enabled technologies for developing a serious game of sailing over ancient Mediterranean and the latter for an underwater shipwreck excavation game. Both games are realized thought social media, in order to facilitate information exchange among users. The project supports dry visits providing immersive experience through VR Cave and 3D info kiosks on museums or through the web. Additionally, aims to significantly enhance the experience of the diver, visitor or scholar, using underwater augmented reality in a tablet and an underwater housing. The consortium is composed by universities and SMEs with experience in diverse underwater projects, existing digital libraries, and people many of which are divers themselves.
Psychophysiological responses to virtual crowds: Implications for wearable computing
Abstract
Human responses to crowds were investigated with a simulation of a busy street scene using virtual reality. Both psychophysiological measures and a memory test were used to assess the influence of large crowds or individual agents who stood close to the participant while they performed a memory task. Results from most individuals revealed strong orienting responses to changes in the crowd. This was indicated by sharp increases in skin conductance and reduction in peripheral blood volume amplitude. Furthermore, cognitive function appeared to be affected. Results of the memory test appeared to be influenced by how closely virtual agents approached the participants. These findings are discussed with respect to wearable affective computing which seeks robust identifiable correlates of autonomic activity that can be used in everyday contexts.
Effectiveness of an Immersive Virtual Environment (CAVE) for teaching pedestrian crossing to children with PDD-NOS
Abstract
Children with Autism Spectrum Disorders (ASD) exhibit a range of developmental disabilities, with mild to severe effects in social interaction and communication. Children with PDD-NOS, Autism and co-existing conditions are facing enormous challenges in their lives, dealing with their difficulties in sensory perception, repetitive behaviors and interests. These challenges result in them being less independent or not independent at all. Part of becoming independent involves being able to function in real world settings, settings that are not controlled. Pedestrian crossings fall under this category: as children (and later as adults) they have to learn to cross roads safely. In this paper, we report on a study we carried out with 6 children with PDD-NOS over a period of four (4) days using a VR CAVE virtual environment to teach them how to safely cross at a pedestrian crossing. Results indicated that most children were able to achieve the desired goal of learning the task, which was verified in the end of the 4-day period by having them cross a real pedestrian crossing (albeit with their parent/educator discretely next to them for safety reasons).
Visualizing and assessing hypotheses for marine archaeology in a VR CAVE environment
Abstract
The understanding and reconstruction of a wrecks formation process can be a complicated procedure that needs to take into account many interrelated components. The team of the University of Cyprus investigating the 4th-century BC Mazotos shipwreck are unable to interact easily and intuitively with the recorded data, a fact that impedes visualization and reconstruction and subsequently delays the evaluation of their hypotheses. An immersive 3D visualization application that utilizes a VR CAVE was developed, with the intent to enable researchers to mine the wealth of information this ancient shipwreck has to offer. Through the implementation and evaluation of the proposed application, this research seeks to investigate whether such an environment can aid the interpretation and analysis process and ultimately serve as an additional scientific tool for underwater archaeology.
Tensor-Cuts: A simultaneous multi-type feature extractor and classifier and its application to road extraction from satellite images
Abstract
Many different algorithms have been proposed for the extraction of features with a range of applications. In this work, we present Tensor-Cuts: a novel framework for feature extraction and classification from images which results in the simultaneous extraction and classification of multiple feature types (surfaces, curves and joints). The proposed framework combines the strengths of tensor encoding, feature extraction using Gabor Jets, global optimization using Graph-Cuts, and is unsupervised and requires no thresholds. We present the application of the proposed framework in the context of road extraction from satellite images, since its characteristics makes it an ideal candidate for use in remote sensing applications where the input data varies widely. We have extensively tested the proposed framework and present the results of its application to road extraction from satellite images.
Towards a more effective way of presenting virtual reality museums exhibits
Abstract
In this work, we present the design, development and comparison of two immersive applications with the use of Virtual Reality CAVE technology: a virtual museum following the traditional paradigm for the museum exhibit placement and a virtual museum where no spatial restrictions exist. Our goal is to identify the most effective method of arranging museum exhibits when no constraints are present. Additionally we will present the significance of the folklore museum in cyprus. Since this would affect the design process.
Immersive visualizations in a VR cave environment for the training and enhancement of social skills for children with autism
Abstract
Autism is a complex developmental disorder characterized by severe impairment in social, communicative, cognitive and behavioral functioning. Several studies investigated the use of technology and Virtual Reality for social skills training for people with autism with promising and encouraging results (D. Strickland, 1997; Parsons S. & Cobb S., 2011). In addition, it has been demonstrated that Virtual Reality technologies can be used effectively by some people with autism, and that it had helped or could help them in the real world; (S. Parsons, A. Leonard, P. Mitchell, 2006; S. Parsons, P. Mitchell, 2002). The goal of this research is to design and develop an immersive visualization application in a VR CAVE environment for educating children with autism. The main goal of the project is to help children with autism learn and enhance their social skills and behaviours. Specifically, we will investigate whether a VR CAVE environment can be used in an effective way by children with mild autism, and whether children can benefit from that and apply the knowledge in their real life.
User experience observations on factors that affect performance in a road-crossing training application for children using the CAVE
Abstract
Each year thousands of pedestrian get killed in road accidents and millions are non-fatally injured. Many of these involve children and occur when crossing at or between intersections. It is more difficult for children to understand, assess and predict risky situations, especially in settings that they don't have that much experience in, such as in a city. Virtual Reality has been used to simulate situations that are too dangerous to practice in real life and has proven to be advantageous when used in training, aiming at improving skills. This paper presents a road-crossing application that simulates a pedestrian crossing found in a city setting. Children have to evaluate all given pieces of information (traffic lights, cars crossing, etc.) and then try to safely cross the road in a virtual environment. A VR CAVE is used to immerse children in the city scene. User experience observations were made so as to identify the factors that seem to affect children's performance. Results indicate that the application was well received as a learning tool and that gender; immersion and traffic noise seem to affect children's performance.
3DUNDERWORLD-SLS: An Open-Source Structured-Light Scanning System for Rapid Geometry Acquisition
Abstract
Recently, there has been an increase in the demand of virtual 3D objects representing real-life objects. A plethora of methods and systems have already been proposed for the acquisition of the geometry of real-life objects ranging from those which employ active sensor technology, passive sensor technology or a combination of various techniques. In this paper we present the development of a 3D scanning system which is based on the principle of structured-light, without having particular requirements for specialized equipment. We discuss the intrinsic details and inherent difficulties of structured-light scanning techniques and present our solutions. Finally, we introduce our open-source scanning system "3DUNDERWORLD-SLS" which implements the proposed techniques. We have performed extensive testing with a wide range of models and report the results. Furthermore, we present a comprehensive evaluation of the system and a comparison with a high-end commercial 3D scanner.
Improving augmented reality applications with optical flow
Abstract
This paper presents an augmented reality application framework which does not require specialized hardware or pre-calibration. Features extracted, using SURF, are matched between consecutive frames in order to determine the motion of the detected known object with respect to the camera. Next, a bi-directional optical flow algorithm is used to maintain the performance of the system to real-time. The system has been tested on two case studies, a children's book and advertisement, and the results are reported.
A framework for automatic modeling from point cloud data
Abstract
We propose a complete framework for the automatic modeling from point cloud data. Initially, the point cloud data are preprocessed into manageable datasets, which are then separated into clusters using a novel two-step, unsupervised clustering algorithm. The boundaries extracted for each cluster are then simplified and refined using a fast energy minimization process. Finally, three-dimensional models are generated based on the roof outlines. The proposed framework has been extensively tested, and the results are reported.
Environment-Aware Design For Underwater 3D-Scanning Application
Abstract
Underwater archaeologists and exploration groups often face a challenge with the documentation and mapping process, which must take place underwater and be able to accurately capture and reconstruct the specific archaeological site. The automation of the scanning and reconstructing process is quite desirable for the underwater archaeologists, however, such automation entails quite a few hurdles from a technological perspective, in terms of data acquisition, processing and final reconstruction of the objects situated underwater. This paper focuses on the design of the 3D scanning application, for the purpose of reconstructing the underwater objects/scenes, such that it is environment-aware. By environment-aware the paper refers to the identification of aspects of an underwater environment that need to be considered in a 3D scanning process and, furthermore, the designing of a system that considers these aspects when scanning objects/scenes found in underwater environments. In this process, several decisions need to be made, with regards to the setup, the method and the analysis, considering issues that may arise in such environments.
Addressing lens distortion through the use of feed-forward neural networks for calibrating underwater scenes
Abstract
Underwater archaeologists often face a challenge with the documentation process, which must take place underwater and be able to accurately capture and reconstruct an archaeological site. The automation of the scanning and reconstructing process is desirable, however, it entails quite a few hurdles from a technological perspective, in terms of data acquisition, processing and final reconstruction of the objects situated underwater. This paper focuses on the system calibration process, as the first step towards a successful automation attempt, and in particular on lens distortion and how to eliminate this from the calibration process. Existing analytical solutions that approximate lens distortion values, might not be able to capture such distortions faithfully, and in underwater environments where the water's refractive index causes a magnification of image features, the analytical approximation of distortion values becomes even more challenging. The neural network approach proposed aims to simplify the calibration procedure for such environments by eliminating lens distortion prior to system calibration, without compromising precision in the subsequent calibration process.
Improving Augmented Reality Applications on Commodity Hardware With Optical Flow
Abstract
This paper presents an augmented reality application framework which does not require specialized hardware or pre-calibration. Features extracted using SURF are matched between consecutive frames in order to determine the motion of the detected known object with respect to the camera. Next, a bi-directional optical flow algorithm is used to maintain the performance of the system to realtime. The system has been tested on two case studies, a children's book and advertisement, and the results are reported.
3D reconstruction of urban areas
Abstract
Virtual representations of real world areas are increasingly being employed in a variety of different applications such as urban planning, personnel training, simulations, etc. Despite the increasing demand for such realistic 3D representations, it still remains a very hard and often manual process. In this paper, we address the problem of creating photorealistic 3D scene models for large-scale areas and present a complete system. The proposed system comprises of two main components: (1) A reconstruction pipeline which employs a fully automatic technique for extracting and producing high-fidelity geometric models directly from Light Detection and Ranging (LiDAR) data and (2) A flexible texture blending technique for generating high-quality photorealistic textures by fusing information from multiple optical sensor resources. The result is a photorealistic 3D representation of large-scale areas(city-size) of the real-world. We have tested the proposed system extensively with many city-size datasets which confirms the validity and robustness of the approach. The reported results verify that the system is a consistent work flow that allows non-expert and non-artists to rapidly fuse aerial LiDAR and imagery to construct photorealistic 3D scene models.
Digitizing the Parthenon: Estimating Surface Reflectance under Measured Natural Illumination
Abstract
This edition presents the most prominent topics and applications of digital image processing, analysis, and computer graphics in the field of cultural heritage preservation. The text assumes prior knowledge of digital image processing and computer graphics fundamentals. Each chapter contains a table of contents, illustrations, and figures that elucidate the presented concepts in detail, as well as a chapter summary and a bibliography for further reading. Well-known experts cover a wide range of topics and related applications, including spectral imaging, automated restoration, computational reconstruction, digital reproduction, and 3D models.
Delineation and geometric modeling of road networks
Abstract
In this work we present a novel vision-based system for automatic detection and extraction of complex road networks from various sensor resources such as aerial photographs, satellite images, and LiDAR. Uniquely, the proposed system is an integrated solution that merges the power of perceptual grouping theory (Gabor filtering, tensor voting) and optimized segmentation techniques (global optimization using graph-cuts) into a unified framework to address the challenging problems of geospatial feature detection and classification. Firstly, the local precision of the Gabor filters is combined with the global context of the tensor voting to produce accurate classification of the geospatial features. In addition, the tensorial representation used for the encoding of the data eliminates the need for any thresholds, therefore removing any data dependencies. Secondly, a novel orientation-based segmentation is presented which incorporates the classification of the perceptual grouping, and results in segmentations with better defined boundaries and continuous linear segments. Finally, a set of gaussian-based filters are applied to automatically extract centerline information (magnitude, width and orientation). This information is then used for creating road segments and transforming them to their polygonal representations.
Automatic creation of massive virtual cities
Abstract
This research effort focuses on the historically-difficult problem of creating large-scale (city size) scene models from sensor data, including rapid extraction and modeling of geometry models. The solution to this problem is sought in the development of a novel modeling system with a fully automatic technique for the extraction of polygonal 3D models from LiDAR (Light Detection And Ranging) data. The result is an accurate 3D model representation of the real-world as shown in Figure 1. We present and evaluate experimental results of our approach for the automatic reconstruction of large U.S. cities.
Photorealistic large-scale Urban city model reconstruction
Abstract
The rapid and efficient creation of virtual environments has become a crucial part of virtual reality applications. In particular, civil and defense applications often require and employ detailed models of operations areas for training, simulations of different scenarios, planning for natural or man-made events, monitoring, surveillance, games, and films. A realistic representation of the large-scale environments is therefore imperative for the success of such applications since it increases the immersive experience of its users and helps reduce the difference between physical and virtual reality. However, the task of creating such large-scale virtual environments still remains a time-consuming and manual work. In this work, we propose a novel method for the rapid reconstruction of photorealistic large-scale virtual environments. First, a novel, extendible, parameterized geometric primitive is presented for the automatic building identification and reconstruction of building structures. In addition, buildings with complex roofs containing complex linear and nonlinear surfaces are reconstructed interactively using a linear polygonal and a nonlinear primitive, respectively. Second, we present a rendering pipeline for the composition of photorealistic textures, which unlike existing techniques, can recover missing or occluded texture information by integrating multiple information captured from different optical sensors (ground, aerial, and satellite).
Automatic reconstruction of cities from remote sensor data
Abstract
In this paper, we address the complex problem of rapid modeling of large-scale areas and present a novel approach for the automatic reconstruction of cities from remote sensor data. The goal in this work is to automatically create lightweight, watertight polygonal 3D models from LiDAR data(Light Detection and Ranging) captured by an airborne scanner. This is achieved in three steps: preprocessing, segmentation and modeling, as shown in Figure 1. Our main technical contributions in this paper are: (i) a novel, robust, automatic segmentation technique based on the statistical analysis of the geometric properties of the data, which makes no particular assumptions about the input data, thus having no data dependencies, and (ii) an efficient and automatic modeling pipeline for the reconstruction of large-scale areas containing several thousands of buildings. We have extensively tested the proposed approach with several city-size datasets including downtown Baltimore, downtown Denver, the city of Atlanta, downtown Oakland, and we present and evaluate the experimental results.
A vision-based system for automatic detection and extraction of road networks
Abstract
In this paper we present a novel vision-based system for automatic detection and extraction of complex road networks from various sensor resources such as aerial photographs, satellite images, and LiDAR. Uniquely, the proposed system is an integrated solution that merges the power of perceptual grouping theory(gabor filtering, tensor voting) and optimized segmentation techniques(global optimization using graph-cuts) into a unified framework to address the challenging problems of geospatial feature detection and classification. Firstly, the local presicion of the gabor filters is combined with the global context of the tensor voting to produce accurate classification of the geospatial features. In addition, the tensorial representation used for the encoding of the data eliminates the need for any thresholds, therefore removing any data dependencies. Secondly, a novel orientation-based segmentation is presented which incorporates the classification of the perceptual grouping, and results in segmentations with better defined boundaries and continuous linear segments. Finally, a set of gaussian-based filters are applied to automatically extract centerline information (magnitude, width and orientation). This information is then used for creating road segments and then transforming them to their polygonal representations.
Rapid creation of large-scale photorealistic virtual environments
Abstract
The rapid and efficient creation of virtual environments has become a crucial part of virtual reality applications. In particular, civil and defense applications often require and employ detailed models of operations areas for training, simulations of different scenarios, planning for natural or man-made events, monitoring, surveillance, games and films. A realistic representation of the large-scale environments is therefore imperative for the success of such applications since it increases the immersive experience of its users and helps reduce the difference between physical and virtual reality. However, the task of creating such large-scale virtual environments still remains a time-consuming and manual work. In this work we propose a novel method for the rapid reconstruction of photorealistic large-scale virtual environments. First, a novel parameterized geometric primitive is presented for the automatic building detection, identification and reconstruction of building structures. In addition, buildings with complex roofs containing non-linear surfaces are reconstructed interactively using a nonlinear primitive. Secondly, we present a rendering pipeline for the composition of photorealistic textures which unlike existing techniques it can recover missing or occluded texture information by integrating multiple information captured from different optical sensors (ground, aerial and satellite).
Linear feature extraction using perceptual grouping and graph-cuts
Abstract
In this paper we present a novel system for the detection and extraction of road map information from high-resolution satellite imagery. Uniquely, the proposed system is an integrated solution that merges the power of perceptual grouping theory (gabor filtering, tensor voting) and segmentation (graph-cuts) into a unified framework to address the problems of road feature detection and classification. Local orientation information is derived using a bank of gabor filters and is refined using tensor voting. A segmentation method based on global optimization by graph-cuts is developed for segmenting foreground(road pixels) and background objects while preserving oriented boundaries. Road centerlines are detected using pairs of gaussian-based filters and road network vector maps are finally extracted using a tracking algorithm. The proposed system works with a single or multiple images, and any available elevation information. User interaction is limited and is performed at the begining of the system execution. User intervention is allowed at any stage of the process to refine or edit the automatically generated results.
Generating high-resolution textures for 3d virtual environments using view-independent texture mapping
Abstract
Image based modeling and rendering techniques have become increasingly popular for creating and visualizing 3D models from a set of images. Typically, these techniques depend on view-dependent texture mapping to render the textured 3D models in which the texture of novel views is synthesized at runtime according to different view-points. This is computationaly expensive and limits their application in domains where efficient computations are required, such as games and virtual reality. In this paper we present an offline technique for creating view-independent texture atlases for 3D models, given a set of registered images. The best texture map resolution is computed by considering the areas of the projected polygons in the images. Texture maps are generated by a weighted composition of all available image information in the scene.Assuming that all surfaces of the model are exhibiting Lambertian reflectance properties, ray-tracing is then employed, for creating the view-independent texture maps. Finally, all the generated texture maps are packed into texture atlases. The result is a 3D model with an associated view-independent texture atlas which can be used efficiently in any application without any knowledge of camera pose information.
The Parthenon - Short animation
Abstract
"The Parthenon" is a short computer animation which visually reunites the Parthenon and its sculptural decorations, separated since the early 1800s. The film used combinations of time-of-flight laser scanning, structured light scanning, photometric stereo, inverse global illumination, photogrammetric modeling, image-based rendering, BRDF measurement, and Monte-Carlo global illumination in order to create the twenty-some shots used in the film.